Hashing and Encryption: A Likely Pair
Hashing and encryption are distinct disciplines. Indeed, the differenced between hashing and encryption can be stark:
According to the SSL Store, “encryption is a two-way function where information is scrambled in such a way that it can be unscrambled later. Hashing is a one-way function where data is mapped to a fixed-length value primarily for use in authenticating values. “
Due to their natures however, hashing and encryption find harmony in cryptography. This article describes hashing, its synergy with encryption, and uses in IRI FieldShield for enhancing data protection. You can learn about data encryption techniques in FieldShield here.

What is Hashing?
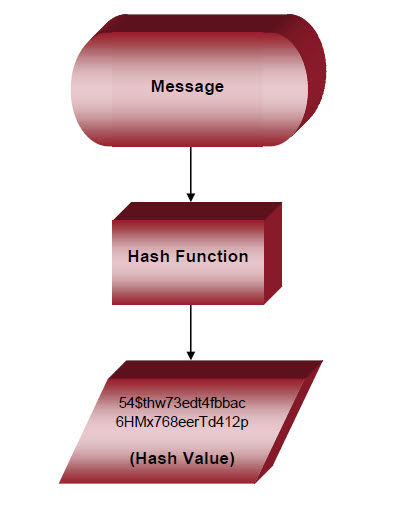
Hashing turns variable input data (known as the “message” or “pre-image” … for example, a password) into fixed length, obscure alphanumeric strings called the message digest, or “hash value” (index look-up for the message).
It is difficult to divine the original value from the hash value not only because of the obfuscation, but because sometimes a single hash value can represent more than one message. The “associative array” of “buckets” in which these hash (value, index) pairs are kept uses a data structure called a hash table.
In this obfuscation context, hashing’s ability to represent data as an apparently random string of letters and numbers makes it appear analogous to encryption. Indeed, encrypting the same values (for the purpose of securing them) also involves computational scrambling of the original.
However, hashed results are unique for each value, and can take different forms. Moreover, an encrypted value cannot be revealed without the corresponding decryption algorithm and common key. Reverse hashing is not so reliable.
In general, hashing and encryption functions overlap when they are used for security. According to Wikipedia, so called “cryptographic hash functions” can:
“have many information security applications, notably in digital signatures, message authentication codes (MACs), and other forms of authentication. They can also be used as ordinary hash functions, to index data in hash tables, for fingerprinting, to detect duplicate data or uniquely identify files, and as checksums to detect accidental data corruption. Indeed, in information security contexts, cryptographic hash values are sometimes called (digital) fingerprints, checksums, or just hash values, even though all these terms stand for functions with rather different properties and purposes.”
The ideal hash function is one-directional, and should not have an inverse function that can be used to decode the hash value (digest). This strength characteristic is known as “pre-image resistance.”
Better cryptographic hash functions also have “second pre-image resistance.” This makes it harder to find another message with the same digest even if you have a message and the hash function.
Also important is “collision resistance.” This is a broader version of second pre-image resistance, where the hash function produces a one-to-one value from its domain of possible messages to the range of fixed-length hash values.
There are many algorithms for cryptographic hash functions; two of the more powerful families of algorithms include Secure Hash Algorithm (SHA) and Merkle–Damgård (MD). These have high resistance all-around and are advancing with the cryptographic needs of the next generation of computing.
IRI supplies an SHA-256 hashing algorithm with its FieldShield, DarkShield, and CellShield data masking tools, along with a wide range of encryption functions, including 3DES, format preserving AES-256, GPG, and OpenSSL.
Generally, the relative strength, need for reversibility, and even the appearance of the resulting ciphertext, make encryption functions a more popular choice for message protection and recovery. Hash functions become valuable in a secondary, or complimentary protection role, where they are used instead to identify whether someone has tampered with the message (or the encrypted version of it).
That is why hash functions are often used to generate checksums or Message Authentication Codes (MAC), which are created and sent along with messages like emails, EFTs, or passwords. When the message is received, its contents are run through the same function to create a new MAC. If the original and new MACs match, the message is authentic; if they do not, the message is likely to have been altered, and thus compromised.
How FieldShield Users Can Apply Hashing
In the FieldShield context, a hash function could be used to create a MAC for one or more fields in each record. This MAC can be included as an additional field in the record structure, or provided in a separate file. It could later be used to verify that the data in the record had not been tampered with.
This approach can help protect data values from being tampered with as they move through a system (not just when the file was transferred, loaded, etc.), and even after encryption. The hash generation criteria would need to remain a protected secret to prevent someone from being able to modify the data and the digest at the same time.
Another use for hash values are as a digital proxy, or surrogate key, for identifying records. Suppose that we need to analyze several tables of data, and that sensitive data is included in the key. Assume that:
1. there are multiple tables or files of data, of a relational nature; and,
2. the key fields used to link the data together contain personally identifiable information (PII).
This is basically the same scenario as encrypting key fields in a relational data model, except that a hash could combine compound key fields into a single field. The length and nature of the key data would have to be such that hash collisions were precluded.
The hash digest can take the place of the PII, in all source tables or files. The data can then still be joined and analyzed, using the hash digest as a surrogate for the original PII.
So yes, FieldShield users can actually apply the built-in SHA-256 function to protect PII and other sensitive field values directly. But most FieldShield users prefer encryption, pseudonymization, redaction, scrambling, blurring, and other data masking methods to protect field values to their business rules.
Considerations for choosing each field’s protection method include its resulting appearance, security, reversibility, and the time it takes to protect (and reveal) the data. Hashing in the FieldShield context plays its strongest role as a message authenticator, to validate the integrity of encrypted values and to authenticate decrypted values.
Additional contributors to this article were FIT intern Roby Poteau and IRI engineer Don Purnhagen. The following additional references were consulted:
Preneel, B., The State of Cryptographic Hash Functions, Lectures on Data Security, 1999, Springer-Verlag, pg. 6 <citeseerx.ist.psu.edu>
Rogaway, P., Shrimpton, T., Cryptographic Hash-Function Basics: Definitions, Implications, and Separations for Preimage Resistance, Second-Preimage Resistance, and Collision Resistance, 2004, <http://www.cs.ucdavis.edu/~rogaway/papers/relates.pdf>
Schaffer, C., et al., Hash Tutorial, Last updated: 10/27/2011, <http://research.cs.vt.edu/AVresearch/hashing/About.php>
The MD6 Hash Algorithms, < http://groups.csail.mit.edu/cis/md6/>
Secure Hash Algorithm, < http://www.nist.gov/itl/>










