Masking Data in Pentaho
This article is second in a 3-part series on using IRI products to expand functionality and improve performance in Pentaho systems. We first demonstrate how to improve sorting performance, and then introduce ways to mask production data, and create test data, in the Pentaho Data Integration (PDI) environment.
Pentaho Data Integration (PDI) can do typical data transformations; however, it does not appear to have a native ability to mask or encrypt data flowing through Kettle. The need to protect data at risk, even in data integration scenarios, is expanding amid a plague of data breaches.
IRI FieldShield software provides many different data masking options for Pentaho users. You can call FieldShield job scripts from the Shell step in Pentaho to protect data at rest (in database and other structured sources).
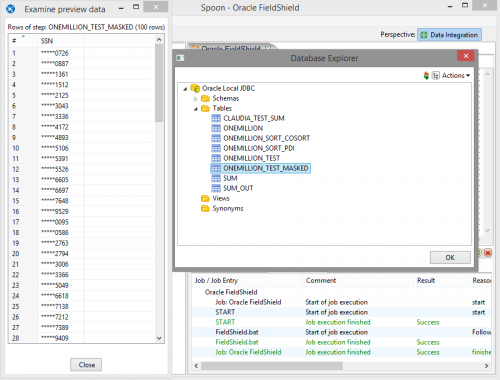
As you can see by exploring your data source in Pentaho, sample Social Security Numbers are fully displayed.

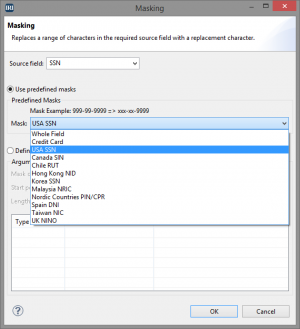
Using FieldShield, you can mask/encrypt/encode (and others) this data in your needed format. There are some predefined masks that make redacting all or part of an SSN extremely easy.

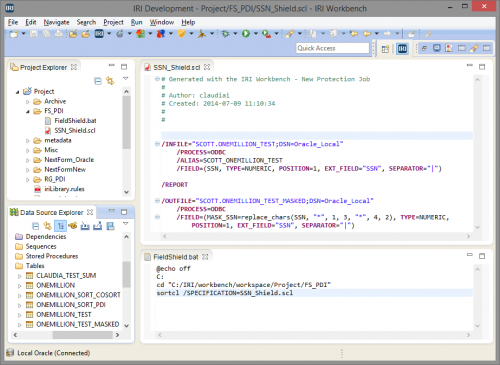
The script created in the IRI Workbench – the Eclipse GUI for FieldShield and other IRI software — gets run by Pentaho through the Shell step which executes a batch file. This batch file is not automatically created by the FieldShield wizard; however, this is easily created in the Workbench with four lines of code.
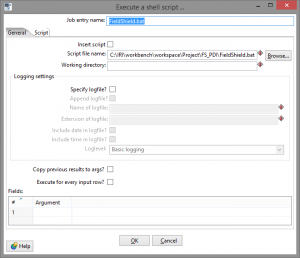
The only step that is needed to mask your data is a Shell step. Below is a simple job; however, the Shell step can be added to any of your jobs. The Shell step simply references the batch file to run during execution.

After executing the Pentaho job, the FieldShield job has now masked the data via the protection method selected in the FieldShield wizard.
The IRI Workbench has multiple options for data masking at the field level, along with other data life-cycle management activities, including: bulk database extraction and load acceleration, data transformations, data quality improvement, data and database migration, data replication, test data generation, data federation, and reporting. Any of these operations could be run alongside Pentaho to improve its efficiency.
Click here if you missed the previous blog on improving sort performance in Pentaho, or see the third article on creating test data for Pentaho.










