Weighted Distribution of Test Data Values in RowGen
Realistic test data has a number of advantages over real data for anyone creating or changing a database, prototyping ETL operations, or testing applications. First, synthetic data do not expose personally identifiable information (PII) like credit card, social security numbers, birth dates, etc. Second, realistic test data shows how the system will behave with real data elements and the relationships between them. Third, generated test data can expand the number of rows and the range of values needed to fully-stress test future system capabilities.
With respect to data value ranges, real world data are not usually distributed evenly between the minimum and maximum values. There are often averages, medians, standard deviations, and variations that may need to be factored into the distribution. Distributions can be flat, normalized or even weighted, depending on the characteristics of the data being tested. And there are many other sophisticated distribution patterns that may reflect the nature of data in a given application. Regardless, test data that hopes to be realistic must reflect the anticipated distribution of generated values that occur in real data.
In IRI RowGen v3, there are several options for controlling the distribution of numeric or character values to approximate their occurrence rate (or spread) in the real world. Users can specify distributions for one or more fields using the New Custom Test Data Job wizard — used when building realistic test data layouts on an ad-hoc basis. Or, these same options can affect like columns (based on pattern matching rules) across multiple tables in the New DB Test Data Job wizard. Here, structurally and referentially correct test data are generated to conform to the formats and relationships in production databases. Applying weighted distributions enhances data realism among non-key fields in this case.
The ‘New Distributions Wizard’ in RowGen allows you to select, and then add specifications for, the following distribution types, each with its own dialog:
Linear
A simple dialog that allows you to specify a linear distribution. The options are:
Min value and Max value: The lowest and highest values in the distribution.
Precision: Allows the user to select the number of decimal places or significant digits of the generated numbers.
Normal
This dialog support two variations of a normal, or bell curve, distribution:
1) Normal distribution for a range, with the options:
Min value, Max value, and precision
2) Normal distribution for mean and standard deviation, with the options:
Mean: The average value within all the generated values
Standard Deviation: Set the standard deviation from the mean
Precision: Select the decimal precision of the generated numbers
Weighted Distribution of Numeric Values
Random numeric values are generated from the user-defined space, which can consist of one or more smaller spaces. Each defined entry describes that smaller space using percentage-based ranges of numeric values, with flexible min and max ranges for each:
Percentage: The relative percentage (weighting). At 20%, for example, one fifth of all generated values for that column will fulfill the criteria below. The total number of values generated is defined by ‘number of records to generate ‘ in the Source options dialog.
Beginning min value and Ending min value: For setting the ‘left’ and ‘right’ minimum values (for slanted-shape distributions at the low end of the range).
Beginning max value and Ending max value: For setting the ‘left’ and ‘right’ maximum values (or slanted-shape distribution at the top end of the range). Note that keeping the two min values the same, and the two max values the same, will suffice for most approximation purposes.
As many entries (with the above criteria) as needed can be specified and stored in a reusable set file (in case the same distribution values are needed in other test data generations). The Browse… feature imports an existing set file, eliminating the need to enter parameters manually.

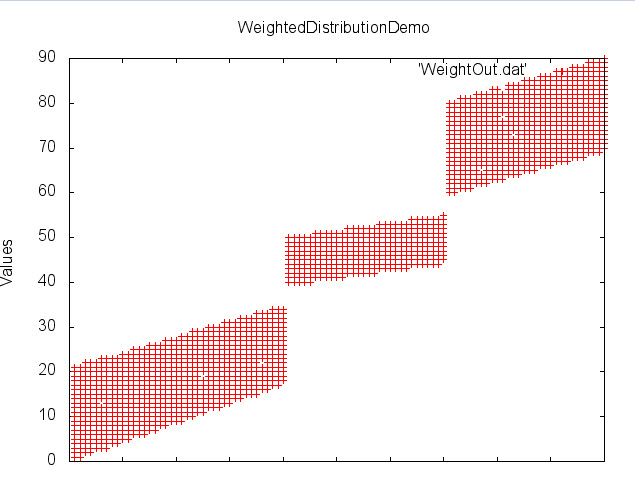
When creating a weighted distribution of numeric field values, all relevant parameters for each data cluster are specified, and must total 100%. Otherwise, RowGen may create random outlier values (that do not conform to the desired parameters). In the example above, three numeric data sets are created:
- The first set represents 40% of the test data values with minimums set at 1/18 and maximums set at 21/35.
- The second set represents 30% of the data with minimums set at 40/45 and maximums set at 50/55.
- The third set represents 30% of the data with minimums set at 60/70 and maximums set at 80/90.
The preview option opens a gnuplot graph showing the value distributions within the test data to be generated:

Weighted Distribution of Items
This dialog controls the occurrence rate of certain literal values in relation to others. For example, it can specify that, regardless of the number of test rows generated, the data will contain a 4:1 ratio of males to females.
The options are:
Ratio: for setting the occurrence ratio of the value. Percentages must add up to 100.
Value: for entering the literal value to be generated according to the relative ratio.
As many entries (with the above criteria) as needed can be specified and stored in a reusable set file (in case the same distribution values are needed in other test data generations). The Browse… feature imports an existing set file, eliminating the need to enter parameters manually.
This ratio example sets the occurrence percentages in the state column at 50:40:10 for California, New York, and Texas, respectfully:

RowGen v3 offers wizards for easily generating realistic test data for different targets. The test data created not only reflect production layouts and relationships at any volume level (with realistic minimum and maximum values), but also support user-defined data points reflecting the distribution of real data. This helps create testing environments that are as realistic as possible.
For more information on RowGen, see www.iri.com/products/rowgen and www.iri.com/products/rowgen/gui.