Optimizing Transforms in DataStage with CoSort
Comparing Filter/Sort/Join/Aggregate Performance
ITKeySource, an ETL consultancy in Jacksonville, FL, recently benchmarked relative performance gains running IRI CoSort — and its SortCL program in particular — alongside IBM DataStage.
CoSort has been used for years in this capacity in high volume data transformation environments, like this one on Solaris. But in this case, we tested them with this:
Hardware:
-
- Dell PowerEdge R230 Server
- Intel® Xeon® E31230 v5 3.4GHz, 8M cache, 4C/8T
- 16GB 2133MT/s UDIMMs
- 1TB 7.2K RPM SATA 6Gbps 3.5in
and
Software:
-
- IBM InfoSphere DataStage® and QualityStage® 8.7
- IRI Voracity® 1.0 & CoSort® 9.5.3
- IRI Workbench, a free GUI option, built on Eclipse™:
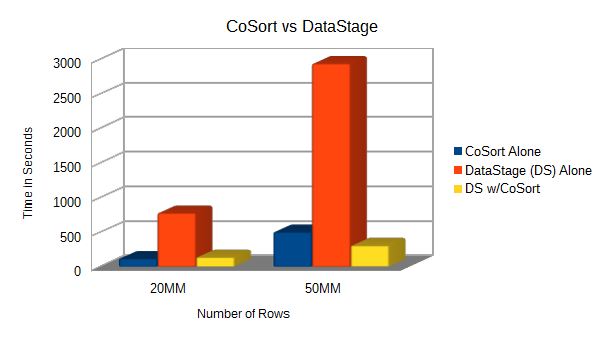
In this POC, I transformed flat files with combined row counts of 2MM, 5MM, 20MM, and 50MM in the CoSort SortCL program, IBM DataStage, and then together from within DataStage. Below are the times it took to sort, join, aggregate, and filter two input files and create two output files:
|
Rows |
Left File |
Right File |
CoSort Alone |
DataStage (DS) Alone |
DS w/CoSort |
|
2MM |
76.8 MB |
13.8 MB |
11 seconds |
22 seconds |
12 seconds |
|
5MM |
192 MB |
344.7 MB |
29 seconds |
60 seconds |
32 seconds |
|
20MM |
76.8 MB |
1378.8 MB |
122 seconds |
780 seconds |
140 seconds |
|
50MM |
1920 MB |
3447 MB |
406 seconds |
2940 seconds |
310 seconds |
In addition to the speed differences, which I try to account for in this article, I also explain the methodology by which I ran the same transform jobs … first alone, and then together. Before I do that, it should be noted that the raw data used for this job was randomly generated with the same SortCL executable using embedded ‘RowGen’ functionality.1
CoSort Process
The IRI CoSort product — and its SortCL data definition and manipulation 4GL program doing all the transforms — is shown above in the free IRI Workbench Eclipse GUI’s syntax-aware editor.
SortCL is fast primarily because it combines the transforms (and other functionality) in the same job script and I/O pass. It also uses the CoSort engine in the file system, which takes advantage of multi-threading, modern memory management and I/O optimization techniques. And, it is not a compiled program.
SortCL jobs can be hand-written, generated via a job wizard, or ETL workflow palette (with an IRI Voracity data management platform subscription2). The scripts are easy-to-read text files you can run (ad hoc or scheduled) in the GUI, or from the command line. That is how I called it in DataStage below.
![]()
The CoSort ‘SortCL’ script is shown above, with an outline, in the IRI Workbench (Eclipse) GUI. IRI Voracity ETL workflow and transform mapping diagrams of the same job are below those. All the metadata is: 1) re-entrant regardless of work-style, 2) manageable in eGit and other repositories, and 3) compatible with Erwin (formerly AnalytiX DS) Mapping Manager software and CATfx templates for spreadsheet-style mapping definition, stratification, and conversion to/from other ETL tools.3
DataStage Process
Below is the DataStage job design required to sort and join the same two sequential files, then aggregate, and finally, filter them before writing out to the same two separate sequential files. In addition to taking longer to build and run those jobs in DataStage, they must be compiled:
![]()
Transforming with CoSort in DataStage
To combine the processes for the benefit of my DataStage operations, I wrote a simple to call my SortCL script to do the transformation ‘magic’ externally. Rather than using a traditional sequential file-stage call, it was more seamless to use a built-in, Before-job subroutine. This allows me to execute CoSort SortCL on the command line (sortcl /spec=join.scl) from my Windows (DOS) or Unix (Korn) shell, even before any DataStage processes begin:
![]()
The benefit of running CoSort in this environment is immediately apparent:

Given the same source data and targets, it is almost 10X faster at the 50-million-row level to in-source transformations to CoSort through a DataStage subroutine.
To process sources with more than 50 million rows, many DW architects would upgrade to either Parallel Extender or run DataStage on a Unix/Linux server license where the hardware provides more power. CoSort runs in those same environments with even more speed, however, and is much less expensive than either alternative.
If you would like more information or have additional suggestions, please provide feedback in the comment form below.
1 IRI RowGen is also a standalone spin-off product using SortCL syntax, a constituent product of the IRI Data Protector Suite, and a supported test data management facility in the IRI Voracity ‘total data management’ (and ETL) platform.
2 The IRI Voracity ETL package uses CoSort SortCL as its default data transformation program, but can also run most of the same jobs without changes in Hadoop MapReduce 2, Spark, Storm, or Tez.
3 Erwin metadata (mapping) conversion templates can automate the re-platforming of DataStage, Informatica, and several other legacy ETL packages, to faster, and considerably less expensive workflows. in Voracity.











2 COMMENTS
[…] other independent DW consultants have with DataStage, Informatica, and Pentaho, I performed multiple benchmarks on large data sets in Talend natively, […]
Thanks for this valuable information. This post is very important because we have a training program starting next week for DW/BI architects who need to know how to improve ETL performance.