Production Analytic Platform #1/4: Process on Par with Information
This is the first of a four-part series of blog articles examining the inherent tradeoffs between data processing and information storage and presentation within traditional ETL paradigms — from the ODS to the data lake. It explains the need for a more modern, blended approach between data integration and virtualization called the Production Analytic Platform, and the benefits of implementing it with IRI Voracity technology. The articles were written in mid-2018 by Dr. Barry Devlin of 9sight Consulting, a leading authority in data warehousing since 1988, and author of “Business unIntelligence: Insight and Innovation beyond Analytics and Big Data.” A podcast and a video supporting these concepts can be found here.
Whether it’s data warehouses or data lakes, most data management experts believe that data (or, more correctly, information) is the foundation of business computing. In my IDEAL architecture1, I consciously placed information as the underpinning “thinking space” of the three—information, process and people—described. I start with the information store and build up from there.
My initial conversation with David Friedland of IRI (The CoSort Company) caused me to pause for thought. At 40 years young, IRI have a different viewpoint. Process, it seems, is their lodestone. IRI’s data manipulation software optimizes data processing into single, rapid-fire jobs and uses memory when possible (but can also stage data on disk). The thought is both familiar and unsettling to me.
Familiar because business people always focus first on action and process. And I also say that my architecture can be read as a story: “People process information.” Unsettling because I struggle to see how one could start from process rather than information. But, what if process and information could be considered as equal—and simultaneous—partners in business computing?
The question is far more than academic noodling. Consider a real-life decision about how to build and populate a data warehouse. The traditional approach starts with data definition and database design, followed by the use of an ETL (extract, transform and load) tool: information is followed by process. Information and process are handled separately. However, if you adopt a data warehouse automation approach, you start by sitting with business people and prototyping the data collection and transformation process, most of which actually occurs within the database itself. In this case, information and process are intermixed.
The IRI Voracity data management platform (powered by CoSort or Hadoop engines and built on Eclipse for key data discovery, integration, migration, governance, and analytic requirements) focuses almost entirely on the process of gathering and manipulating data. Perhaps due to its initial roots in the mainframe era, it avoids data stores and databases as far as possible: they are sources and sinks for the data that flows through the process. Everything else happens in memory at maximum speed, optimized for lowest processing cost, and described through a comprehensive language and set of metadata.
Conceptually, IRI Voracity is the antithesis of a data warehouse; it might even be called a data hosepipe! In effect, Voracity is a data processing engine vs. a database engine. The contrast is so stark that it has forced me to revisit my logical concept of a “Production Analytic Platform” and consider how to give information stores and data processing components equal prominence.
The Production Analytic Platform
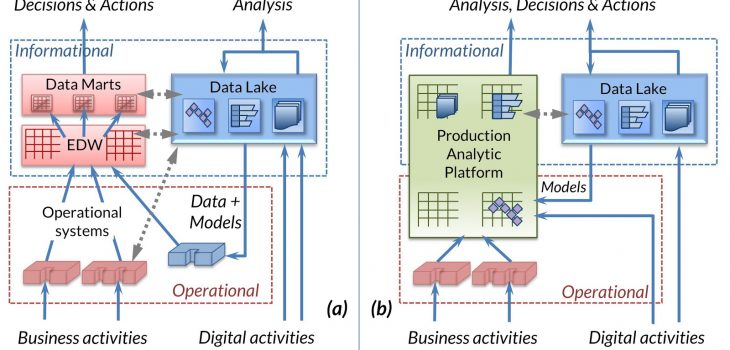
The Production Analytic Platform, which amalgamates the data warehouse and data mart concepts, springs from consideration of how business intelligence (BI) has largely morphed into analytics in the past half-decade or so. Coming from BI’s rearview mirror on past performance, modern analytics demands current data to predict and prescribe future behavior. This demand for real-time data and immediate response challenges the longstanding division of business computing into operational and informational areas, shown below in Figure 1.
Operational systems run the business and are optimized for read-write processing of data. Data warehouses (and marts) in the informational area track and manage the business, and are optimized for write-once / read-many processing. Data lakes—where much of modern analytics occurs—are largely informational in design. While ideal for the model-building phase of analytics, challenges arise when the resulting models must run continuously in a production environment to offer real-time predictions or prescriptions.
Recognizing that both operational systems and data warehouses are today built on high-performance, production-ready relational database management systems (RDBMS), the Production Analytic Platform proposes that RDBMSs, with existing extensions to handle non-relation data and function (such as documents, key-value stores and graphs), are the preferred environment to handle the production phase of analytics, as shown in Figure 2. Further details of the rationale behind and characteristics of this approach can be found in my earlier paper2.
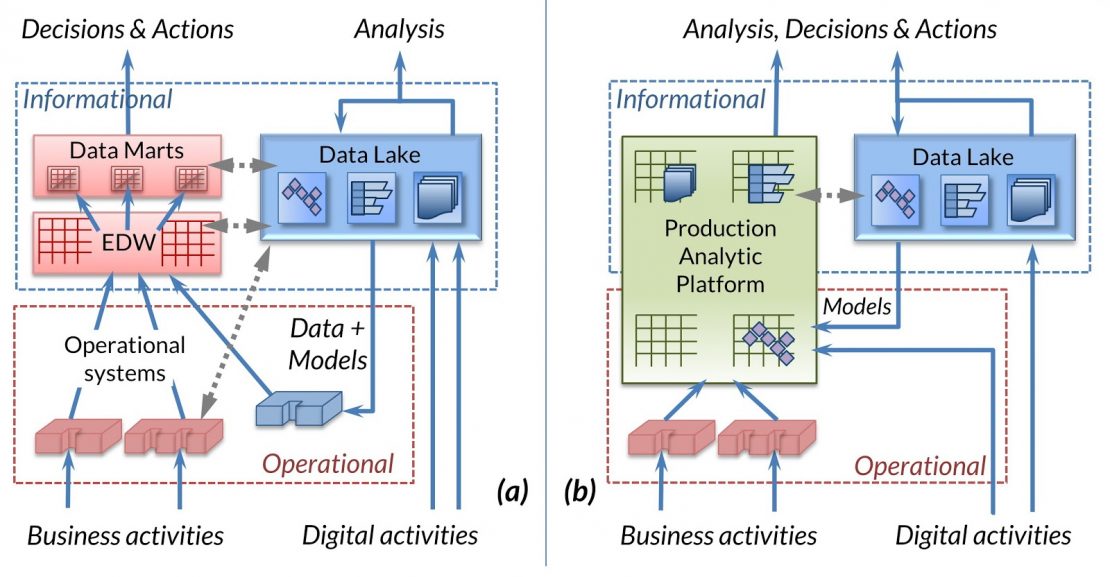
Extending the Production Analytic Platform
Viewing the above figures through a process-oriented lens, a certain data-centric emphasis is evident. Data and its stores comprise the majority of the named components. Data flows are represented by unlabeled arrows, minimizing the significance of the processing that occurs within these flows. Where does this processing take place and how is it defined and managed? Indeed, some processing occurs—almost unnoticed—within the data stores themselves. For example, a primary output of a data warehouse is the reports that drive decisions and actions; producing a report requires, of course, processing of the data in the warehouse.
Extending the Production Analytic Platform as shown in Figure 2 begins to address these issues. At first glance, drawing an additional, extended green box and recoloring and adding and combining some arrows may feel underwhelming! The emphasized arrows suggest that a variety of processing, preparation and delivery functions must be inherently considered in the design of the Production Analytic Platform:
- Data flows from operational systems and digital activities
- Sharing of data and analytical models between the data lake and Production Analytic Platform
- Delivery of information to business users for analysis, decisions and actions
In addition, the partial inclusion of the data lake suggests the multi-platform nature of the Production Analytic Platform, as well as the increasing use of relational technology in the data lake.
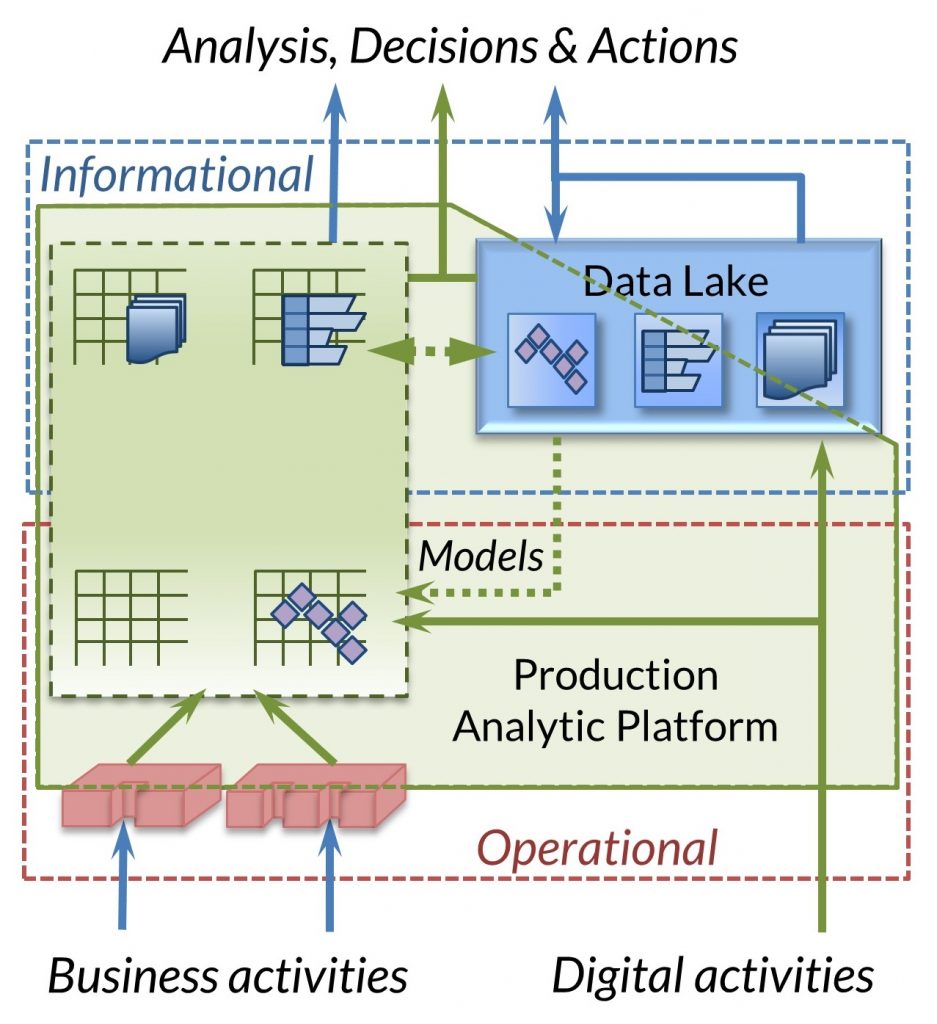
In short, the idea is to allow and encourage new thinking: What would it mean to place process on an equal footing with information? Where would we explicitly place the process needed to prepare data for business use? How many times should identical or largely similar data be physically stored? Is the old division between operational and informational worlds still valid?
Analysis of these issues must be done in the context of the function and features of existing and anticipated technology in both data storage and processing. IRI Voracity offer key insights into a process-oriented view of this environment and allows us to step back from an overly storage-centric assessment.
Next Up … The Search for Efficiency
The following posts in this blog series will explicitly address the above questions. First, we explore how taking a process view opens new possibilities for improving the efficiency of existing data management systems, such as data warehouses and operational systems. We will then explore how operational analytics for externally sourced data can be reinvented. Finally, we examine how a process view helps align traditional ETL and data virtualization.
- Devlin, B., “Business unIntelligence”, Technics Publications, Basking Ridge, NJ, 2013, http://bit.ly/BunI-TP2
- Devlin, B., “Introducing the Production Analytic Platform”, February 2018, http://bit.ly/2Bt29Pi











2 COMMENTS
[…] exists today. Ron Powell, independent analyst and industry expert, conducted this interview. Click here to read more blogs describing this platform developed by Dr. […]
[…] This is part 2 of a 4 part series. See part 1: Process on Par with Information. […]