
A Fresh Look at Data Preparation
To analyze data successfully, it must first be prepared successfully. Poor quality data creates poor results. Worse yet is data that takes too long to collect and clean because it is too big or too foreign. Raw data is usually unfit even for the imagination, much less making decisions.
Traditional BI architects and big data scientists know the solution to this problem lies in good data preparation. Unfortunately, this is a process that rarely comes to mind when people think about data. It’s hardly seductive, or the glamorous side of information today. But it is a necessary step towards the insights people expect to glean from their data. Indeed, before data can become useful, it has to be culled, churned, and cleansed, so the glamorous algorithmic and display magic can happen.

What Exactly is Data Preparation?
Think of the sum of data as a landfill. Data gets thrown in from every possible place. People don’t care about it because it’s easy to send it somewhere else and forget about it. As a result, you wind up with just a dump of information. Not only is most of it useless in its current state, it is also taking up space, possibly in what’s now called a data lake.
Worse still, this data often sits in a pile of various formats and frequently contains duplicates and errors. It’s an unorganized and unmanageable tangle. To call it messy is putting it lightly.

Data preparation solves these problems. It collects data and cleans it. It gets rid of duplicates and errors. It recognizes that “William Bartram,” “Bill Bartram,” and “Bill Bertram” are actually the same person, and it unifies those records. Unstructured data, like phone calls or email, passes through the sieve of preparation and comes out in a database-friendly format. More importantly, though, this data is now becoming valuable.
Data preparation has gone by a handful of names. IRI first used Rick Sherman’s term for it, “data franchising,” when CoSort was preparing data for BI tools in 2003. Now it also appears as data blending, data munging, and data wrangling, among other newer industry buzzwords. But they all mean the same thing. Whichever term you prefer, the core preparation activities should include:
- discover (profile, search, extract, classify)
- pivot, slice and dice
- transform (sort, join, aggregate, pre-calculate)
- cleanse (scrub, unify, validate)
- mask (encrypt, redact, pseudonymize)
against the widest array of sources, with as much customization and automation as possible.
The Value of Data Preparation
Valuable is a pretty vague word. Gold, for instance, is valuable only because we say it is. But a straw is valuable when you have a toddler with a cup because you need it. Companies identify value differently; they extract it according to how it affects the bottom line. Data preparation begins the process of extracting whatever informational value they think that data may yield.
Making data usable is critical to profiting from it. Thorough data preparation assures valid, high-quality information. It helps maximize marketing campaigns by eradicating duplicate prospects and narrowing segments to more precise metrics. It unlocks the value of analytics and self-service BI (business intelligence). It even prepares data for selling, as noted by the expanding field of Infonomics. Selling data alone makes US supermarket chain, The Kroger Co., $100 million dollars in incremental revenue each year.
Data Preparation merges several business-critical objectives. It sources and profiles data, integrates data, governs data, and prepares data for analytics. By investing in data preparation, you invest in your company’s future. Because, no matter your line of business, data is its future.
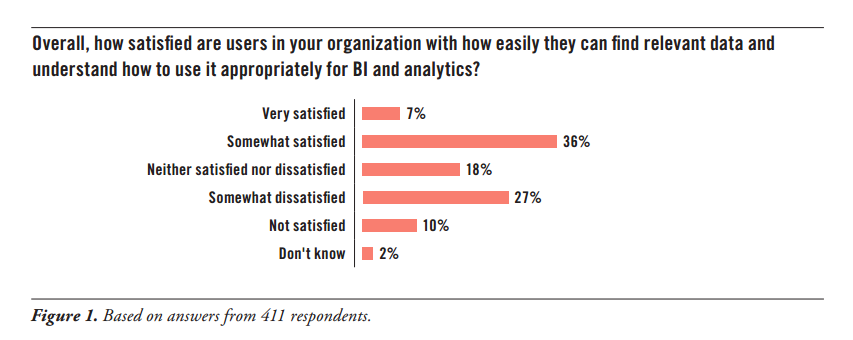
Source: Improving Data Preparation for Business Analytics, TDWI Q3 2016
What’s Holding It Back
At this point, data preparation sounds pretty good. It’s something every serious, data-driven business needs for competitive advantage. And the faster you can consistently and successfully prepare data, the better positioned your company will be to benefit from it.
Many businesses nevertheless struggle to implement data preparation procedures. They are not aware of the volume and variety of data they will face, cannot handle the cost and complexity of tools designed to prepare it, and they do not perceive sufficient ROI from the process.
In its recent report, Improving Data Preparation for Business Analytics, TDWI warned that “insufficient budget is the most common barrier to improving how data is prepared for users’ BI and analytics projects.” The second most common barrier is “not having a strong enough business case.”
This means several things, including the fact that many businesses don’t value their data enough. Their executives do not understand or realize the potential of the data they have. That makes the business user’s tasks of justifying and budgeting for data preparation solutions harder. And when those solutions are expensive, the tasks are all the more arduous. What would help is to have data preparation software that fits the analytic project budget, rather than overwhelms it. That way, a clean business case can be made along with the technical one.
The Technology At Hand
The most common approach to custom data preparation may be none at all. MOLAP, ROLAP, or HOLAP cubes provide immediate “slice and dice” and calculation-based analyses for relational databases; but they are limited in their source scope and performance, and devoid of governance. Otherwise raw or virtual tables at rest, or data federated through a logical data warehouse, are often used as direct fodder for analytic processes or platforms.
Among the tools designed to handle the issue in a DB-agnostic way is IRI CoSort, or the larger IRI Voracity data management platform that uses CoSort or MR2, Spark, Spark Stream, Storm, or Tez in Hadoop to prepare data. They support multi-source data discovery, integration, migration, governance and analytics in both preparatory and presentation frameworks that are typically cheaper, easier to configure, and faster than specialty data preparation and legacy ETL tools.

The benchmarks linked from the tabs in this section show a 2-20X improvement in time-to-visualization by using IRI data preparation software ahead of legacy BI tools and newer analytic platforms — all of which choke or die on big data. Beyond the proven power of this option are the established efficiencies of reusable data. Central data stores avoid handling overhead and synchronization problems that come from integrating data for every report.
For more real-time analyses, API-level tie-ups with BIRT and Boost functions in Eclipse combine data preparation with more advanced, open source presentation. The Voracity add-on for Splunk indexes cloud collections while preparing raw data locally or remotely.
Newer product offerings in the space (like Alteryx, Paxata, and Trifacta), which prepare data for analytics, are also worth a look for what they do and where they run (cloud). However, they would not have the benefit of IRI’s many more years of legacy and big data transformation — or data cleansing and masking — experience. They are also not considered a Production Analytic Platform which Voracity has become …










