
The Use of Data Lakes
Has your organization considered using a data lake? This article explains what a data lake is, and posits a data lake architecture optimized for analytic results. IRI Voracity data management platform users should also be able to assess this approach relative to other data integration paradigms the platform supports, including LDW, EDW, ODS, Data Fabric and Data Mesh.
What Is a Data Lake?
Data lakes are environments for gathering and storing data for experimentation. The term data lake was coined by Pentaho CTO James Dixon. He used the term to compare data that was cleansed, packaged, and structured — like what was found in a data mart (or bottled water) — to data in its more natural state (in a large, real body of water).
“The contents of the data lake stream in from one or more sources to fill the lake, and various users of the lake can come to examine, dive in, or take samples,” Dixon blogged.
Gartner refers to the data lake as “a collection of storage instances of various data assets additional to the originating data sources. These assets are stored in a near-exact, or even exact, copy of the source format.”
Thus, the data lake is a single store of enterprise data that includes both raw data (which implies an exact copy of source data) and transformed data used for reporting and analytics. Some want the data lake to replace the traditional data warehouse, while others see it as more of a staging area to feed data into existing data warehouse architectures.
Data lakes can exist in the file system, a Hadoop fabric, or cloud storage service like Amazon S3.
Why Use a Data Lake?
Traditional architectures silo information into buckets that provide only a fraction of the insight that might be derived from a larger collection of data. Data marts and warehouses require data to be identified, cleansed, and formatted so they fit pre-defined notions of what they represent. Dixon argues that there could be many other valuable notions derived from data found in its unprocessed, natural state.
According to Gartner, the purpose of a data lake is to present an unrefined view of data so skilled analysts can apply their data mining techniques devoid of the “system-of-record compromises that may exist in a traditional analytic data store (such as a data mart or data warehouse).” The data lake removes the constraints of relational structures when various forms of ‘big data’ need to be examined in new ways.
Consolidating traditionally isolated data sources can also increase the sharing and use of information, and reduce the costs of hardware and software holding that data now.
Data lakes thus provide the “opportunity” to not have to prepare and protect all the data an organization gathers, and instead, just save it for later when new needs or ideas arise. Companies that build successful data lakes find they need to gradually mature their lake as they figure out which data and metadata are interesting to their organization.
Red Flags – Governance and Efficiency
There are naysayers who relegate the data lake to a mere notion, particularly since many organizations are unsuccessful with their deployments. Cambridge Semantics CTO Sean Martin said, “We see customers creating big data graveyards, dumping everything into HDFS and hoping to do something with it down the road. But then they just lose track of what’s there.”
As with any major data-driven initiative, the lake will have to be sold across the enterprise. Data lakes absorb data from a variety of sources and store it all in one place, and by definition, without the usual requirements for integration (like quality and lineage) or security. Someone will need to be accountable for governance. Data Vault inventor Dan Linstedt warns, for example:
Users of self-service BI tools trolling the lake have to be governed. Think about who gets to use which tool, who gets to log in where and access what data, or who can open a spreadsheet and upload data directly to Hadoop, and then make it available to the rest of the enterprise. That can be a serious problem.
David Weldon’s April 2017 article in Information Management magazine, “Many Organizations Struggling to Manage Lakes,” affirmed the issue in this quote from Zaloni’s CEO Ben Sharma:
Perhaps the biggest challenge organizations are facing is “finding, rationalizing and curating the data from across an enterprise for analytics solutions … the ability to easily access data, refine data and collaborate on data needs continues to be a large roadblock for many analytic applications.”
This is why governing data in a lake is important, which means, dealing with veracity, security and metadata lineage issues, to name a few. See De-Mucking the Lake, below.
The other issue to consider is performance. Most tools and data interfaces cannot ingest, process, or produce information in an unmanaged lake as well as data in fit-for-purpose (e.g., query optimized) environments. Thus, consistent semantics and an engine like CoSort will help.
Stocking the Lake
Data enter the lake from various sources, including structured data from files and databases (rows and columns), semi-structured data (ASN.1, XML, JSON), unstructured data (emails, documents, and pdfs), or possibly images, audio, and video … thereby creating a centralized store for all forms of data.
IRI Voracity is a data connection and curation platform that can be used to populate a data lake by connecting to, profiling, and moving data in different sources into the lake:
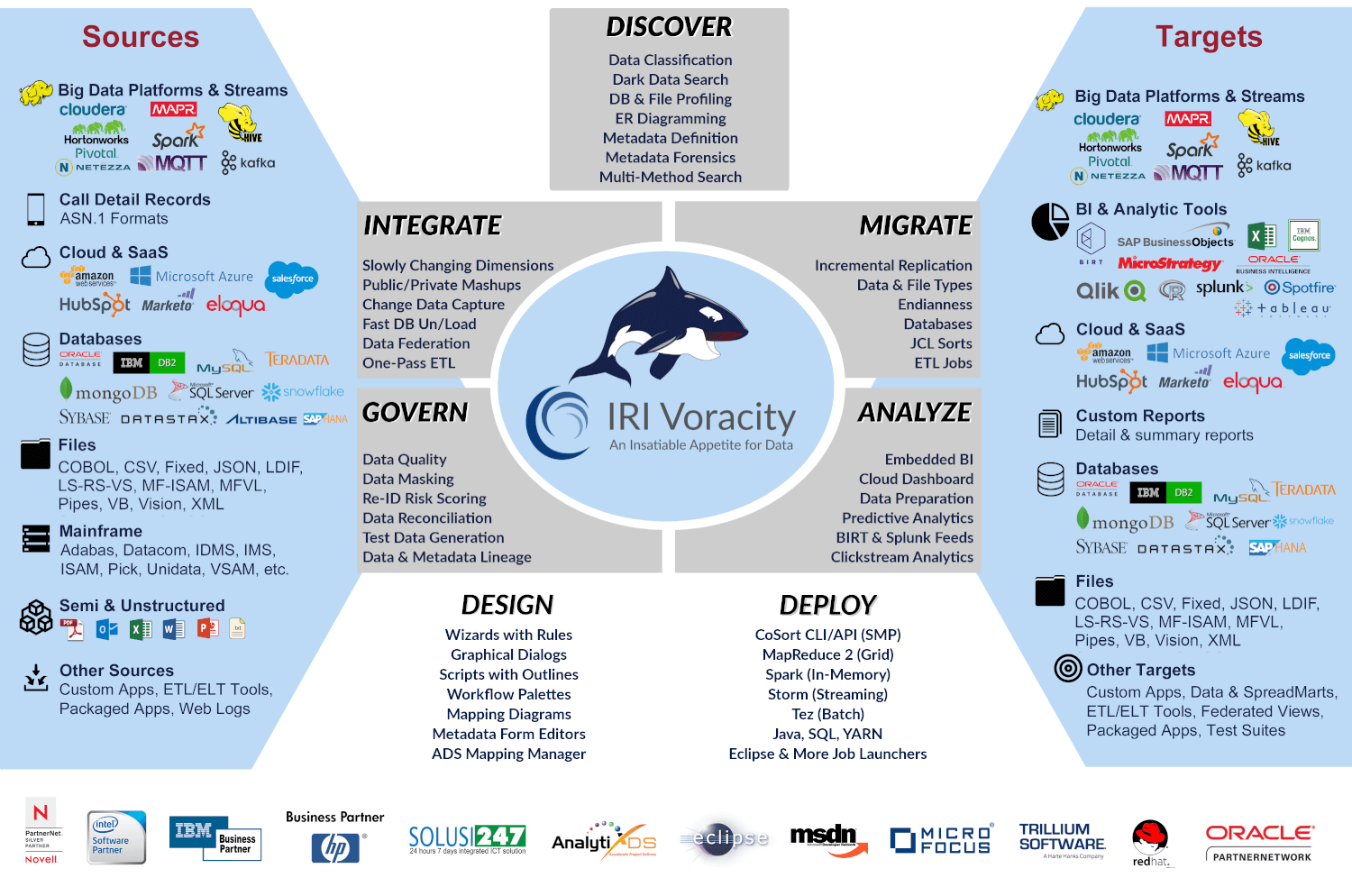
During or after movement, you can select, transform, reformat, and report on data from disparate sources using jobs defined by scripts, wizards, dialogs, or diagrams in Eclipse. You can use Voracity to govern and test-analyze data in the lake, and to move data out of the lake.
Fishing the Lake
Once you’ve defined the lake’s location and what to pump into it, spend some time now and again to see what’s currently in it. Consider what experiments can be run on that data. Use your own data discovery tools — or Voracity’s flat-file, ODBC, and dark (document) data search, statistical, and relationship checking and diagramming tools — before “testing the water.”
Think of this aspect of Voracity as sonar, where you’re trying to find different kinds of data and at different depths (various sources in the lake). Voracity discovery tools classify data, and allow you to fuzzy-search for values from, ODBC and file sources. They also search those and unstructured sources for: explicit strings, values conforming to canned or custom RegEx patterns, and values in a set (lookup) file. Those tools are actually free, since they only require Voracity’s GUI (IRI Workbench), not an underlying CoSort or Hadoop transformation license.
After identifying data in the lake that looks worthwhile, even data scientists can struggle deriving value from it without the benefit of semantic consistency or managed metadata. It is much harder to manipulate or analyze data without them. Voracity wizards auto-create metadata for the collections within, and build ETL, federation, masking, reformatting, and/or reporting jobs that filter relevant data from the lake, transform it into useful information, and display it.
Voracity manipulates data with the CoSort engine (by default) or, optionally, in Hadoop with the same metadata. Plugins to Voracity’s Eclipse “Workbench” GUI also run: Python, R, SQL, Java, shell scripts, SQL procedures, and C/C++ or Java programs. These tools enable you to do more with lake-related data and apps in the same GUI.
De-Mucking the Lake
Recall that a key problem with data lakes, as with real lakes, is that people don’t know what’s in them, or how clean they are. In nature, unknown things in the water can kill the ecosystem. Unknown data dumped into a data lake can kill the project. Dan Linstedt again advises that:
If there’s no structure, there’s no understanding, and there’s no vision for how to apply this data or even understand what you have. It needs to be classified and cleansed in order to do anything with it and turn it into value-added information for the business. To apply any sort of business information to this data, you must begin to stratify, profile, manage, and understand it, so that you can get results from it.
In short you have to have enough trust in the data to trust your analysis. So it’s better to know and manage what’s in the water. If you use Voracity, you can discover, integrate, migrate, govern and analyze data in the lake — or prepare test or production-ready targets for other architectures, like a data warehouse, mart, or ODS — all within a managed metadata infrastructure.
You also want to be able to dredge the data lake clean, at least as much as you can, through various data cleansing operations. You can use Voracity to improve data quality in the lake in these ways:
- Find – discover, profile, and classify data from a quality standpoint
- Filter – remove or save conditionally selected or duplicate items
- Unify – data found by fuzzy match algorithms and set probabilities
- Replace – data found in pattern searches with literal or lookup values
- Validate – identify null values and other data formats by function
- Regulate – apply rules to find and fix data out of range or context
- Synthesize – custom composite data types, and new row or file formats
- Standardize – use field-function APIs for Melissa Data or Trillium
With less garbage in the lake, less garbage will come out in your analytic results, and the water will be cleaner for everyone else, too.
Also from a governance perspective is the issue of finding, classifying, and de-identifying personally identifiable information (PII) in the data sets. Voracity addresses these problems as well, and offers a wide range of rule (and role)- based encryption, redaction, pseudonymization and related data protection functions that can be applied ad hoc or globally to like columns.
Other Conservation Programs
For advanced information architects, Linstedt advocates combining Data Vault with Voracity:
As far as IRI is concerned, I like their solution because we can govern the end-to-end processing in a central place. With that governance comes the ability to manage. Wrap the Data Vault architecture into that mix, and all of a sudden you have standards around your IT, data and information processes, and around the data modeling constructs that are behind the scenes of a future warehouse iteration of this data.
Additional administrative management of the environment is helpful, too:
You need centralized or shareable metadata that persists and can be readily modified. And if you can automate processes that prepare and report on data, then you can leverage process repeatedly for what-if analysis and thus get to improved results sooner.
Voracity’s approach to metadata management is simplified by virtue of its automatic creation, self-documenting syntax, hub support in Eclipse systems like Git for lineage, security, and version control. For more advanced metadata management and automation, Voracity users can leverage a seamless bridge to a graphical lineage and impact analysis environment in Erwin Mapping Manager.
Voracity’s built-in task scheduler allows you to sequence — and fine tune the repetition of — integration, cleansing, masking, reporting, and/or other jobs you might want to run on lake data.
The bottom line is that a data lake can be a helpful place to test new theories about data now in silos. So stock it, mind your visitors, and see what good can surface from the muck.











