
Comparing Big Data Integration Methods
“That’s all you need in life, a little place for your stuff. That’s all your house is, a place to keep your stuff. If you didn’t have so much stuff, you wouldn’t need a house. You could just walk around all the time. A house is just a pile of stuff with a cover on it.” — George Carlin

In the business world, as in our personal lives, we run into the same quandary of what to do with our continually growing amounts of “stuff.” But it’s not a matter to be taken lightly. When that stuff happens to be digital information, upon which we must base our reasoning and business decisions, we quickly see it’s not just its volume or format that matters. There are many other important considerations as well, especially when pondering the best solutions for storing, integrating, and analyzing big data.1
Gartner defines big data as “high-volume, -velocity and -variety information assets that demand cost-effective, innovative forms of information processing for enhanced insight and decision making.”
Even data produced on a daily basis can exceed the capacity and capabilities of many on-hand database management systems. This data can be structured or unstructured, static or streaming, and can undergo rapid change. It may require real-time or near-real-time transformation into business intelligence (BI). All these factors make it necessary for our data integration choices to reflect the actual storage and usage patterns of our data.
Data Warehouses
A core component of analytics and BI is a data warehouse (DW) or Enterprise Data Warehouse (EDW). This centrally-accessible repository, and its simpler, singular, limited form called a data mart, are the oldest and still most widely-used solutions for managing data and creating reports. The EDW also enables uploading for additional data operations and integration through the more basic operational data store (ODS).

Originating in the 1980s, data warehouse architecture was engineered to facilitate data flow from operational systems requiring analysis of massive accumulations of enterprise data. Data is extracted from heterogeneous sources (usually on-premise databases and files) into a staging area, transformed to meet decision support requirements, and stored/loaded into the warehouse. Business users and executives then base their decisions from that data, proving that the EDW is a reliable data integration and storage paradigm for enabling analytic insight.
Most companies continue to use data warehouses today despite their relatively high hardware, software, and design/support costs. Some businesses have become dissatisfied with this paradigm for large-scale information management due to its overhead. And so the EDW architectural model has evolved in recent years from the physical consolidation method to a more logical and virtual one.
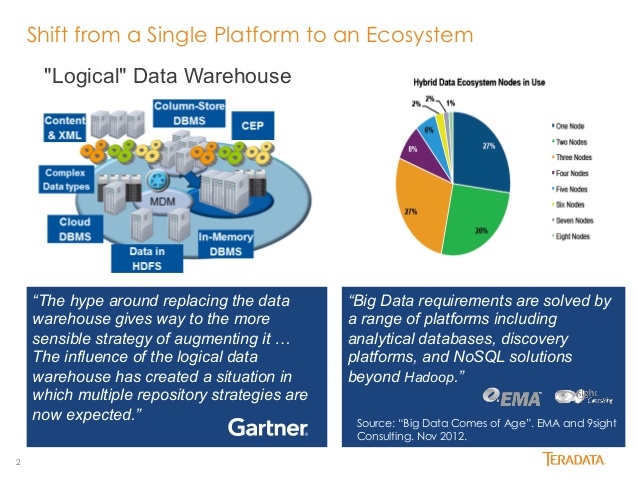
LDW #Trending
Changing requirements in business analytics have created a more modern data virtualization paradigm driven by the demand to easily access and federate data. To complement the traditional data warehouse, the logical data warehouse (LDW) adds an architectural layer to view enterprise data without having to relocate and transform it beforehand. LDWs are capable of retrieving and transforming data in real time (or near-real-time), and producing fresher data without the limitations imposed by the pre-built structures of traditional DWs.
“The Logical Data Warehouse (LDW) is a new data management architecture for analytics which combines the strengths of traditional repository warehouses with alternative data management and access strategy. The LDW will form a new best practices by the end of 2015.” — Gartner Hype Cycle for Information Infrastructure
 Source: Teradata
Source: Teradata
The popularity and use of LDWs continue to increase with cloud-based deployments of analytic environments. This means more disruptions for the data warehouse market as well as new expectations for the LDW. As the number of organizations looking to adopt cloud analytics grows, the potential exists to change the view of the entire industry, and leave some conventional companies behind.
Data Lakes
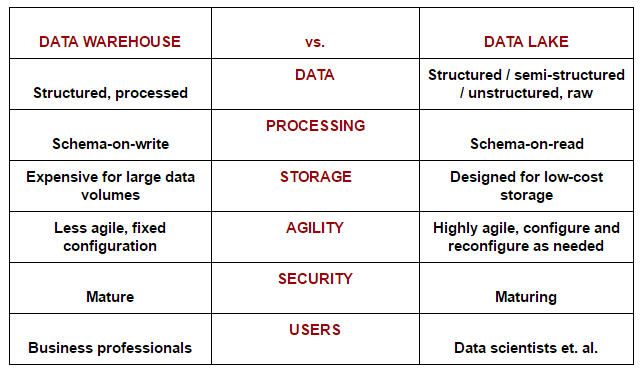
One of the newest approaches to analyzing big data (which may also be stored in the cloud) is the enterprise data lake. Ironically, this data repository method is thought of as a more natural approach since vast amounts of raw data are stored in their native formats until needed. A data lake also uses a flat architecture for storage, unlike the data warehouse, which stores data in a database or hierarchical file system.
Here are some other key differences between a data lake and a data warehouse:2
A lot of companies are now launching data lake initiatives, many as their first Hadoop project. Since Hadoop is an open source data management platform, is it any wonder why businesses are attracted to its (theoretically) cheaper cost and compelling ecosystem? There is no doubting its immediate value for providing a “Data As a Service” solution. However, like other promising platforms, there are inherent problems with using Hadoop for building the enterprise data lake. Some of the crucial elements to making it work right, which are at the heart of the data lake debate, are to regularly sectionize and streamline it for performance, keep the data lake clean and well-organized, and periodically eliminate irrelevant and unusable data.
Ideally, data lakes can achieve company goals by offering great value and flexibility to business teams. With an adequate amount of foresight and planning, as well as strong data governance practices, organizations can automate data lake initiatives enough to handle their size and scope, and thus maximize their business intelligence value.

“Data lakes that can scale at the pace of the cloud remove integration barriers and clear a path for more timely and informed business decisions.” — Brian Stein & Alan Morrison, PwC, Technology Forecast: Rethinking integration, Issue 1, 2014)
Production Analytic Platform
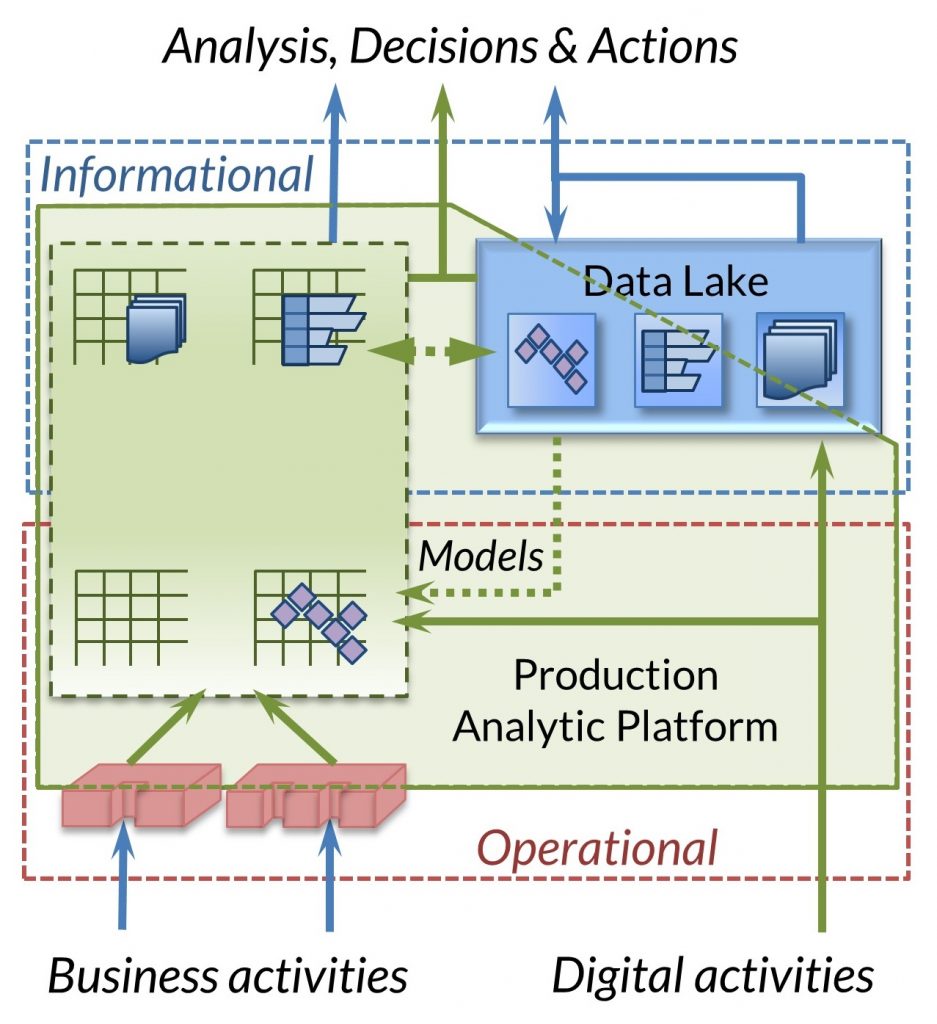 A newer, hybrid paradigm for data integration has been posited by Barry Devlin, PhD, one of the founders of the Data Warehousing industry and author of “Business Unintelligence”3. Dubbed the Production Analytic Platform, his paradigm is a more modern manifestation of the logical data warehouse which attempts to bridge the gap, and end the debate, between the Data Warehouse and the Data Lake, by combining integration and analytics more tightly.
A newer, hybrid paradigm for data integration has been posited by Barry Devlin, PhD, one of the founders of the Data Warehousing industry and author of “Business Unintelligence”3. Dubbed the Production Analytic Platform, his paradigm is a more modern manifestation of the logical data warehouse which attempts to bridge the gap, and end the debate, between the Data Warehouse and the Data Lake, by combining integration and analytics more tightly.
According to Devlin, the purpose of a Production Analytic Platform is to equalize and combine the informational world of using data for insight with the operational one of processing and actioning it. He cited Teradata and IRI Voracity as two such platforms in which analytics were an integral part, and in the latter case, a simultaneous operation with, data integration.
The most recent manifestation of this for big data preparation and visual analytics — as well as data science — is in the Voracity Provider for KNIME, a native data source node built on Eclipse that performs simultaneous ETL, cleansing, masking, and wrangling (staging) to hand-off data in memory to KNIME nodes for immediate predictive analytics, machine learning, deep learning, artificial intelligence, and other data lake experimentation. That simultaneous combination of end-to-end data preparation and presentation activity is potentially game changing for those who view the full lifecycle of big data integration and analytics in both holistic and performance terms.
Oncoming
As new advancements in technology emerge, big data keeps getting bigger. One of the best examples of this is in the “Internet of Things” (IoT), where tens of billions of devices are transmitting information. This in turn is creating more storage options, usually in the cloud. But storing all that data is only the beginning of course.
In the case of IoT, leveraging it means being able to integrate it in the ways described above. But it also about raises opportunities for efficiency improvements like aggregation the edge, and challenges for data security. The key is having agile strategies that allow you to effectively utilize as much of that stored data as possible … and to enable your business to achieve its information-driven goals within the compliance frameworks of the future.
It is inevitable and perennial, in life and in business, that there will always be more and more data, and newer better ways to store and leverage it through integration methodologies. Think about which one will help you use that data in the ways that matter most to you. Give IRI a call if you need some help.










