Speeding Time-to-Display in Power BI
Power BI is a business analytics and data visualization package from Microsoft that can provide custom-designed dashboards and reports ready for web or mobile display. Like other BI and analytic tools, Power BI can also perform simple data wrangling jobs like sorting and aggregation before and after the data are displayed. However, and as with other BI tools, these operations can drag or crash given “big data” sources.
When multiple or high-volume data sources need to be acquired, integrated, cleansed or masked, it pays to perform this preparatory work outside the BI layer. Since 2003, BI and data warehouse architects have relied on the IRI CoSort data manipulation utility — or more recently the IRI Voracity data management platform powered by CoSort or Hadoop — to wrangle raw data ahead of — and then hand-off display-ready subset to — BI tools. The result of such centralized processing has been a 2-to-20X speed up in their times to display (and thus insight).
This article, like others linked from the data wrangling section of the IRI website, benchmarks the time difference in producing a Power BI dashboard from the same data sets, with and without wrangling them with the default CoSort or Voracity data manipulation program, SortCL. SortCL is a high-speed processing engine for structured and semi-structured data that runs on Windows, Linux and Unix command lines. Its work is directed in simple 4GL job scripts, which can also be designed and managed in a graphical IDE built on Eclipse™ called IRI Workbench.
For this experiment, I used CSV source files of increasing size1 to test the relative processing speeds and scalability of SortCL and Power BI. My test files contained three transaction items (fields): department, store number, and sales by department. This is meant to simulate data for a department store where sales are tallied by department and by store.
System Configuration
OS: Windows 7 x64
RAM: 8GB
Processor: Intel i7-2600 @ 3.4 GHz, 4 cores, 8 threads
Pre-Processing with IRI
External data transformation tasks like sorting and aggregations are specified in SortCL scripts produced automatically in wizards like the New Sort Job wizard in IRI Workbench. Once created, you can easily modify, share, and run these jobs on any Windows, Linux or Unix host on which the back-end IRI engine is licensed.
Data sources supported by IRI are listed here.
The following IRI Workbench screenshot shows my sorting and aggregation (data wrangling) job finishing at the 10M-row level in 21 seconds.

I saved my aggregated results to CSV targets for Power BI to read like any other file or database:


Power BI displays the results in three seconds.

Pre-Processing in Power BI
Power BI had two main modes: the Power BI Desktop View and the Power Query Editor. The Query Editor allows the user to edit the imported data and perform various query related task. The Desktop is where numerous custom visualizations and charts can be shown. Not only can it show visuals but it can also perform quick filters, calculations, and aggregations of it’s own using the provided data.
Before a job can be done with Power BI, two steps must be followed. The first is selecting a database table or file and manipulating it. Sources include a variety of databases and file types:

After a data source is selected, you are presented with a preview of a query and given options on what to edit or aggregate.

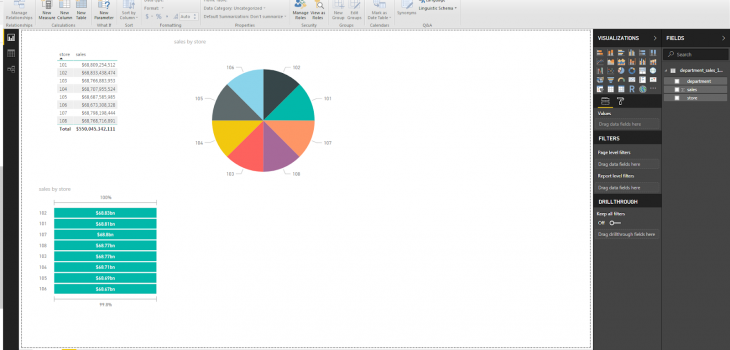
The next step is to apply the changes made with the “Query Editor”. This will process the data from the source and make any changes. Once that is done, the screen will now show the “Desktop”. Here I display the results for the total sales of each store along with with the same two graphs:

It should be known that all data that is used in Power BI must go through the Query Editor before it is seen in the Desktop View.
Like SortCL, Power BI can also solve many common summary calculations and aggregations while processing the data it is reading in. This includes sums, averages, minimum, maximum, and counts. While this means longer processing times, it also means that these summaries can be displayed on the fly in the graphical representations.
Interestingly, many of the query related task that are available in the Query Editor can also be use in the Desktop View. Knowing this, I ran different aggregations, filters, and calculations in the Query Editor mode to see if it would be faster than doing the same in desktop view. It was not, as most calculations and aggregations I created did not improve processing speed. And when I tried a query to produce the same results of my aggregation job, it took longer than just passing the original data to the Desktop view.
For example, creating a summary aggregation of each store in a 5M-row example (150MB) took two minutes in the Query Editor. Sending it to the Desktop took another 1m:14s. That’s over three minutes to complete the same calculation, as opposed to just sending the original data straight to the Desktop, which takes 20 seconds to complete, or using SortCL which took 6 seconds.
A similar slowdown occurs if a new column is created in the Query Editor mode. If any aggregation is performed in a new column, it takes much longer to send the resulting data to the Desktop view. Using the 5M-row example again, it took 20 seconds to send the unmodified data to the Desktop view. If I add a new column with a calculation, that time increased to 34 seconds.
In a much larger 100M-row example (3GB), the difference was more dramatic. It took about 5m:15s for the data to pass straight to the Desktop view and 10 minutes if a calculated column is added. Strangely, if the same calculated column was created in the Desktop view, the processing time is only a few seconds.
Big Data Breakdown(s)
When trying to modify a column in the Query Editor for a 300MB or larger file, Power BI failed to finish the job. It stated the percentage complete but rarely passed the 90% mark. However, if column modifications are not made, it will pass the data over to the Desktop view just fine.
A second point of failure can be found in the Desktop view. Similar to the failure in its Query Editor, Power BI had difficulty creating new columns or “measurements” after reading a file larger than 300MB unless the project was saved. The software sometimes became unstable, froze, produced error messages, or even crashed. Sometimes it worked fine, however.
It should also be noted that saved projects start to become slow and unstable around 8GB. This does not include the summaries automatically created from passing the data from Query Editor to the Desktop view.
Speed Comparisons
As explained before, my test case summarized total sales from a set of stores and produced a grand total of all sales using different input file sizes.
On small inputs, most aggregations in Power BI Desktop take a few seconds or less to perform. However, to get to this point, the source data must be read in by the Query Editor process even if nothing is changed.
As input volumes increased, depending on the size of the data source and whether Power BI could handle it at all, it takes 2-3 times longer to just pass data to the Desktop view than it took an IRI SortCL program to aggregate or filter that same input data.
Below are the average times it took to sort and summarize sales numbers in differently sized files using SortCL and the two different methods that Power BI supports to do the same task. The times shown represent how long it took both products to produce the same data set that Power BI displayed in the visual charts shown above.

Note that Power BI failed in Query Editor mode when doing these aggregates at the 300MB level on my machine. That is why the graph below shows only one line for the Query Editor aggregation; it could only perform grouping at 150 MB. SortCL does not register in blue on the far left only because 6 seconds were too low to show at this scale.

Conclusion
The SortCL program in IRI CoSort or Voracity can help improve the reliability of, and the time to display in, Power BI by performing larger data transformation jobs externally. As my simple comparisons demonstrate, SortCL took only seconds to sort, aggregate, and write its results into a file or database table that Power BI can display. This is far more efficient than preparing the same data in Power BI itself (when it works).
A best practice for BI architects with high volumes of source data is to employ a high-performance data wrangling tool to handle these preparatory workloads ahead of time. In other words, use a fast, fit-for-purpose data manipulation program like SortCL, and then analyze the results in the visualization tool you prefer.










