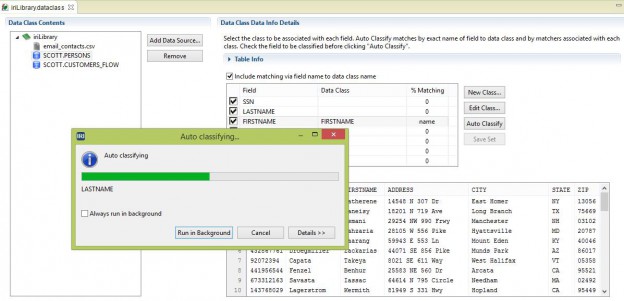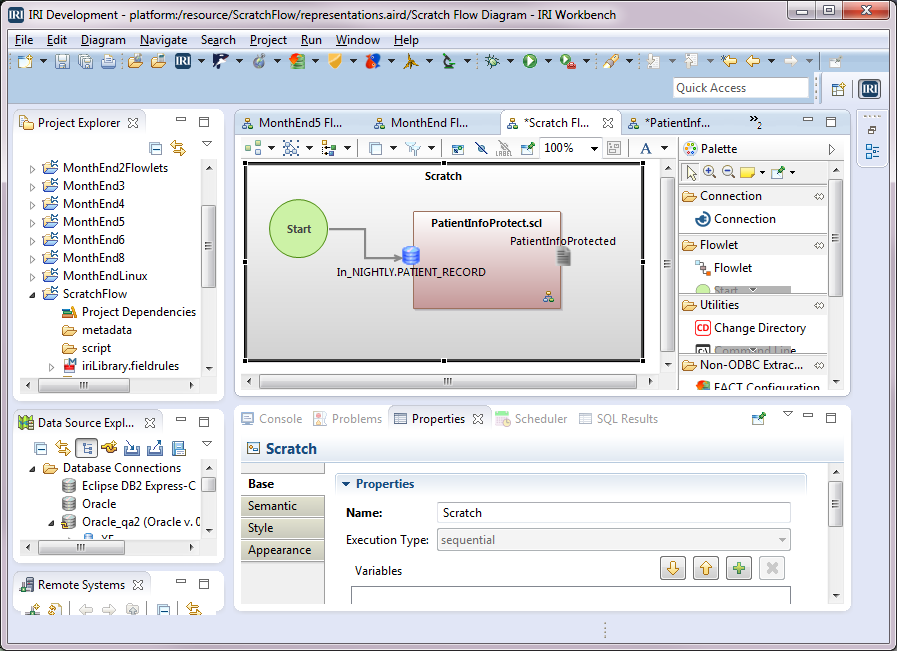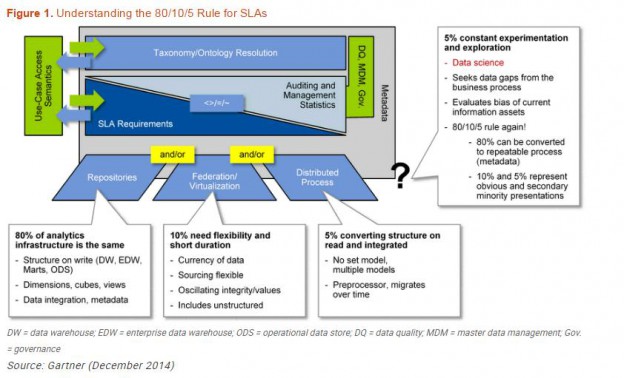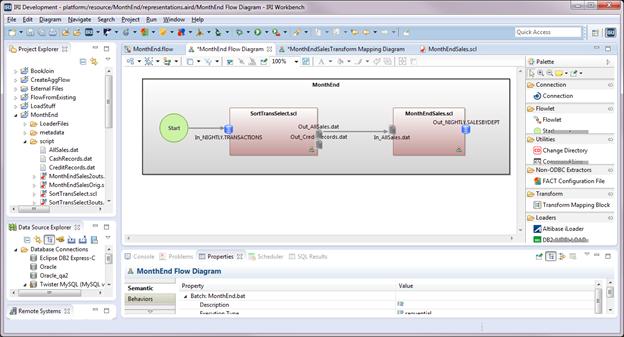
Creating a Voracity Flow Using Existing IRI Scripts (Part…
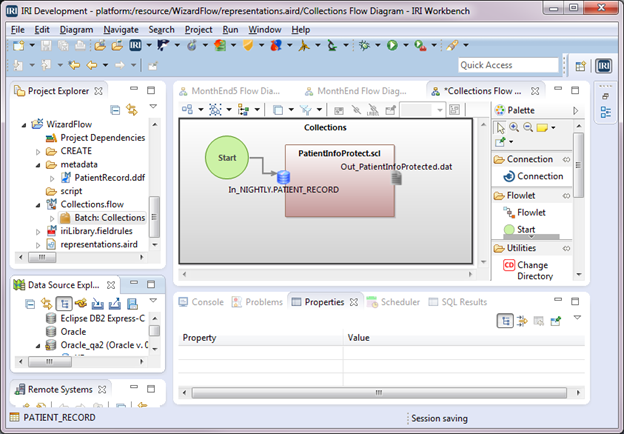
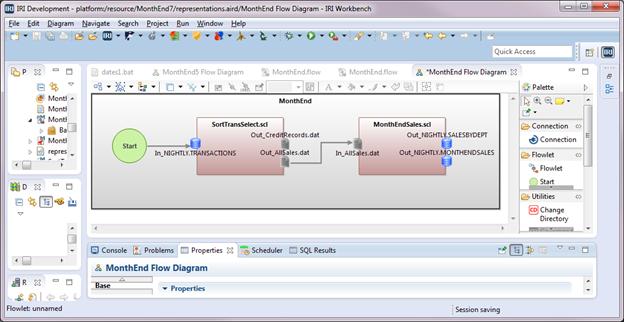
This is the third in a series of articles for creating an IRI Voracity ETL flow of a month-end job for processing sales transactions.
In the first article, we brought an existing CoSort SortCL job script that processes month-end sales transactions into Voracity and made modifications. Read More