Anonymizing Indirect Identifiers to Lower Re-ID Risk
Editors Note: This articles covers data anonymization as a form of data masking for privacy protection. In particular, it covers the concepts of quasi-identifiers and re-identification risk and the use of HIPAA data de-identification standards for protecting sensitive data in research through the use of anonymizing techniques like age blurring and demographic attribute blurring in conjunction with re-ID risk scoring.
Quasi-identifiers, or indirect identifiers, are personal attributes that are true about, but not necessarily unique, to an individual. Examples are one’s age or date of birth, race, salary, educational attainment, occupation, marital status and zip code. Contrast these to direct, unique identifiers like a person’s full legal name, email address, phone number, national ID, passport or credit card number, etc.
Most consumers are already aware of the risks of sharing their unique, personally identifiable information (PII). The data security industry is typically focused on those direct identifiers, too. But with just gender, date of birth and zip code, 80-90% of the US population can be identified.
Almost anyone can be re-identified from an otherwise masked data set if enough indirect identifiers remain and can be joined to a superset population with similar values.
The HIPAA Expert Determination Method rule pertaining to protected health information (PHI) and FERPA law regarding student data privacy contemplate these concerns and require that datasets have a statistically low likelihood of re-identifiability (below 20% is the standard today). Those wishing to use healthcare and educational data for research and/or marketing purposes need to comply with those laws but also rely on the demographic accuracy of the quasi-identifiers for the data to be valuable.
For this reason, data masking jobs in the IRI FieldShield product or IRI Voracity (data management platform) can apply one or more additional techniques to obfuscate the data, while still keeping it accurate enough for research or marketing purposes. For example, numeric blurring functions create random noise for specified age and date ranges, such as described in this article.
Building upon the article here, this example will show how IRI Workbench can create and use set files to anonymize quasi-identifiers.
Start in the Generalization via Bucketing Wizard, available from the list of data protection rules:

Once the wizard opens, begin to define the source of the values for the set file, including the source format and the field requiring a generalized replacement value.

On the next page, there are two kinds of set file substitutions: Use set file as group and Use set file as range options. This example makes use of the Use set file as group option. The article on data blurring demonstrates the Use set files as a range option. The lookup sets built here will be used to pseudonymize the original quasi-identifiers with the new generalization value.
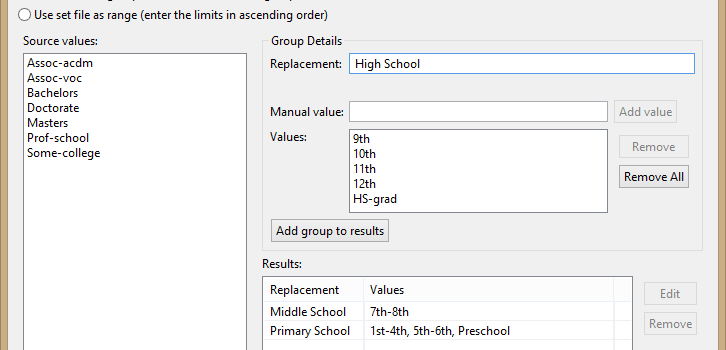
This page is where the groupings among each of the original quasi-identifying field values is created. On the left are the unique values in the previously selected field. The groups can be created by either dragging and dropping into the group values on the left, or by manually entering values. Each group also needs a unique replacement value. This is the value that will replace the original value in the group. In this example, any value of “9th” will be replaced with “High School”.

Adding groups until all the source values are covered produces the following lookup set file for anonymizing the education status quasi-identifier:

If additional levels of bucketing are required, the bucketing wizard can be run again using this set file as the source.
When the set file is used in a data anonymization job, the source data is compared to values in the first column of the set file. If a match is found, the data is replaced with the value in the second column. The above set file is used in the script below on line 38.
Using Workbench to apply five different anonymization techniques results in the following script:

The first ten lines of the original data are show here:

The anonymized results after running the job are shown here:

Prior to these generalizations, the risk of re-identification based on the original indirectly identifying values was too high. But when the more generalized result set is re-run through the risk scoring wizard to produce another determination of re-identification risk, the risk is acceptable and the data is still useful for research or marketing purposes.
If you have any questions about these functions or re-ID risk scoring, contact fieldshield@iri.com.










