Find & Mask File PII in the DarkShield GUI
IRI DarkShield includes fit-for-purpose facilities in the graphical IRI Workbench IDE that build jobs to search (classify) and mask (remediate) PII and other sensitive data in “dark data” sources. Gartner defines this as data not normally used for analytics; i.e., what is usually collected and stored in semi-structured and unstructured sources.
The file formats containing strings that this wizard can search, extract, and mask, include:
- Free-form text (.txt)
- Microsoft Word documents (.doc and .docx)
- Adobe Portable Document Format (.pdf)
- Extensible Markup Language (.xml)
- Microsoft Excel spreadsheets (.xls and .xlsx)
- Microsoft PowerPoint presentations (.ppt and .pptx)
- JavaScript Object Notation files (.json)
- Various image formats (.bmp, .gif, .jpg, .png, and .tif)
- Parquet (.parquet)
- DICOM (.dicom)
These sources can exist in on-premise networks, cloud storage platforms, and within databases.
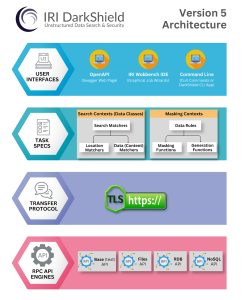
The diagram below summarizes DarkShield’s architecture as part of the overarching Voracity platform, where the wizard this article explains is inside Workbench:
Though not discussed in this article, DarkShield also includes wizards for finding and masking sensitive data in relational and NoSQL databases; i.e., the New NoSQL Search/Masking Job … wizard for MongoDB, Cassandra and Elasticsearch, and the New Relational DB Search/Masking Job … wizard for JDBC-connected databases.
What the DarkShield Files Wizard Does
The “New File Search/Masking Job …” wizard builds XML DarkShield job configuration file with a .dsc extension. Each .dsc file contains the Search and Mask Contexts used in a DarkShield Job.
Search Contexts contain the access instructions for your File System source silo and searching for PII in it. Mask Contexts contains instructions for masking PII that were found during the search, as well as the access instructions for your File System target silo (where masked data will be written).
File system silos supported through the Workbench include local or networked drives, as well as files in SharePoint Online, OneDrive, S3 buckets, Azure Blob Storage, and Google Cloud Storage.
The scanning and remediation of your dark data files is based on the search matchers and masking rules that you define in the IRI Data Class and Rule Library in your Workbench project folder. See this article on data classification for details.
Each Data Class contains one or more search methods used to identify PII. Previous iterations of the wizard only supported scanning and extracting sensitive values that matched Java RegEx patterns and Set File lookups. Today’s wizard supports more search methods, and of course simultaneous or separate masking operations.
For more information on the various search methods available read about Data Matchers and Location Matchers.
Prerequisites
Before launching the DarkShield RDB wizard ensure these preliminary steps are completed:
First, verify that the DarkShield API distribution directory has been specified in IRI Workbench Preferences > IRI > DarkShield. From here you can configure DarkShield GUI and API preferences including the host, port, and directory where the DarkShield API resides.

Second, all DarkShield Wizards require a project possessing an IRI Data Class and Rule Library. The IRI Library in turn should contain at least one Data Class and a Rule that can be assigned to that Data Class. To learn more about the IRI Data Class and Rule Library and creating Data Classes and Rules, read this article.

IRI Project containing the Data Class & Rule Library

IRI Data Class and Rules Library Form Editor contains some Data Classes and Rules
Third, verify that the Plankton server (DarkShield) is running. This can be done by opening the DarkShield API Status view in IRI Workbench. The DarkShield API Status view will display information about the DarkShield API, including whether it is currently running:

DarkShield API Status view panel
Finally, ensure the data silos that you will be reading from and writing to can be accessed by an application (in this case DarkShield API). Depending on the file storage type (i.e. S3 Bucket, SharePoint Online, .etc), various information must be provided to allow the appropriate library to facilitate the connection and retrieval of files.
Using the Wizard
In this article, I will demonstrate the use of the New File Search/Masking Job… wizard to create a DarkShield Files Job.

To open the wizard, select the DarkShield menu dropdown and select the New Files Search/Masking Job… wizard. This brings up the first page where you can name the new job:

Here you will also specify the folder and file names for the output of the wizard.
Click Next to move into the data source specification (files to be masked) page of the wizard.

This page lets you customize a flat-file search log by selecting metadata attributes of the files in which PII was discovered. These attributes will be displayed as columns in a flat text log file containing the values (and specified metadata) from the search operation. The default delimiter is a pipe (“|”) but you can change that.
Note that the RESULT attribute contains the actual PII value found, so if you do not wish to persist PII in the search report, do not select RESULT.
You can select as well whether the wizard will generate a Data Definition Format (DDF) file, which is a metadata repository defining the layout of the flat file containing your search results. DDF syntax is recognized by, and used directly in, SortCL data transformation and reporting jobs.
The /FIELD names in the DDF file will correspond to the keywords and patterns you searched, as well as the forensic attributes that you selected in this dialog to be part of that output log/report.
Note DarkShield search jobs also produce another log (with no PII) in JSON called annotations.json.
Click Next when finished to move into the specifics of the data you are trying to find — and how it should be masked.

In the Data Class and Masking Rule Selection dialog, you will define the contents of your project’s IRI Data Class and Rule Library. This library contains Data Classes and/or Data Class Groups, and the data masking functions/rules you assign to them.
You can filter the Data Classes and Groups from the library that you intend to use by selecting or deselecting Data Classes in the Active column. In this example, I am using all default Data Classes provided when creating an IRI Project.

In the Masking Rules tab, we can see that two functions are available: a Format Preserving Encryption Rule and a Blur Date Rule. These rules dictate how PII found using Data Classes will be masked. It is also possible to add or remove Masking Rules from this tab.
Click Next when finished to move onto the page that will allow you to assign these Masking Rules to specific Data Classes.

On the Assign Masking Rules to Data Classes wizard page, each Data Class and Data Class Group must be assigned a Masking Rule indicating how the PII will be masked or transformed. If you do not wish to modify a particular PII data type, click Back and deselect the Active checkbox associated with that Data Class or Data Class Group; then, return to this page and finish assigning Masking Rules to Data Classes.
Once finished click Next to begin specifying the location(s) of the files to be searched and masked.

From this page we can choose to add, edit, or remove data sources that will be searched through by DarkShield.
If we click Add… a sub-wizard will appear.

From this page, you can specify the file storage type and a connection registry.
DarkShield currently supports the following file storage types:
- Local File System
- OneDrive
- SharePoint Online
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
A Connection Registry is a reusable connection configuration for connecting a data silo. To create a new Connection Registry first select the desired file storage type, then click New.
The example below demonstrates accessing files in the local (PC’s) file system, but DarkShield supports other (cloud) file sources (listed above) in Workbench. The DarkShield-Files API can support files that reside in other storage silos, plus streaming sources, using custom code.

Local File System Storage Type
In the example above, we can see a File Connection Registry requires a path to a directory. The directory in question may contain files or files with more directories. The Include and Exclude fields use regex patterns to either dictate what files to include or exclude based on the file name, respectively.
As seen in the example above the Exclude field has a Regex pattern that will be used to exclude any files ending with error.log from the DarkShield job. This can be useful when certain files should not be subjected to masking.
Recursive lookup should be checked for DarkShield to process files in directories nested inside other directories.
Lastly, you can scroll through the list of file types supported by DarkShield and choose which file types should be processed by checking on or off for each file type. Once your location and file types are selected, click Finish to create the connection registry that was configured. Then on the previous page click Finish.
Afterward, the connection registry information will be displayed on the Data Sources page.

This source item reveals my root directory from which the searches will occur. It is also possible to add additional sources for the search here.
When finished, click Next to open the Filter Selection dialog:

JSON, XML, CSV, and Excel files can have their search scope reduced by specifying one or more filters here. This can decrease the time it takes to finish a job and assist in preventing false positives.
Click Add… to specify a new filter. For JSON, specify a JSON path. For XML, specify an XML path. For CSV, specify a column name regex pattern. For Excel files, there are multiple options for filtering the scope of a search to certain sheets, cell ranges, or columns (by header name).
Clicking Remove deletes the selected filter from the table. When ready click Next and move onto the Data Targets page.
Click Add to create or select a target location. Selecting a target is optional if you are only interested in performing search-only operations.
You must specify a target if masking will be performed. The steps to add a data target are the same as the steps to create a data source, with the exception that file type selection is not requested (since it will be in the same format as the source).

The Add … options allow additional target specifications.
Note that multiple sources and targets can be specified in the wizard. DarkShield will search and mask all files found in the source URIs and replicate the masked files across all of the data targets. The sources and targets can be any combination of file storage types.
At this point you can click Finish to produce a .dsc file or click Next to move to the File Search/Mask Configurations page.
The final page of the new File Search/Masking Job wizard is the optional File Search/Mask Configurations page to further define job attributes applicable only to certain file types, like PDF documents, or image formats like DICOM; see Optional Search/Mask Configurations which follow. These attributes can be stored for reuse in a configuration registry.
Here (and only recommended for advanced users or specific requirements), you can define file configuration options for certain file types. However, DarkShield jobs will use reasonable defaults in the absence of any explicit configurations set. To specify these options, you can select from an existing Dark Data File Configuration option registry entry, or create a new one.

If you opt to create a New … entry, the File Configuration Option Selection page will appear. On this page, select the types of file configuration options to specify, and enter a name for the Dark Data File Configuration registry entry.

After clicking Create, the wizard will open all pages relevant to the file specific configurations for the formats you select here. More details about what each file configuration option does can be found by scrolling to the bottom of this article or by visiting the DarkShield API docs (webpage reachable at localhost:8959/docs by default while DarkShield server is running).
At this point, you are ready to click Finish to produce the .dsc file that is used by the DarkShield API.

DarkShield Job Editor
Every .dsc file can be viewed from a DarkShield Job editor. This editor allows you to modify your DarkShield job parameters after you complete the steps of the DarkShield Files Wizard; e.g.,

You can add, edit, or remove sources and/or targets from your .dsc file as desired by clicking Add, Edit, or Remove (see above). You can also modify your Data Class Rule Mappings (see below).

From the editor, you can also modify your Data Class Rule Mappings by clicking the Modify button. It is also possible to choose a different IRI Library and/or rearrange the Masking Rules assigned to your Data Classes.
The editor also has another section that allows the adding, editing, or removal of file-specific path filters (JSON, XML, Excel, CSV/TSV):

Finally, the editor also provides a preview option that allows you to test your Data Class search matchers and Masking Rules using text input:

By clicking Preview, you can see what PII was found and how it was transformed using the current Data Classes and Masking Rules.
Running Your Search and Masking Jobs
You can use your DarkShield job configuration in three different ways; i.e., in a:
- Search Job to simply identify PII and log the results to file. Be aware of search results logged to file (.*annotations.json) from a search job, may contain PII found in your data source(s). DarkShield (Base) and File API will save JSON files in your workspace but DarkShield NoSQL and RDB API will store search results to directory specified in DarkShield API configuration file.;
- Masking Job that will use the search log to mask the discovered PII; or,
- Search and Masking Job to search and mask PII in one job.
In this demonstration, we will be running a DarkShield Search and Mask Job. To run a DarkShield Search and Mask Job right, click the .dsc file and select IRI > Run Search and Masking Job.

After running a Search and Mask Job, the PII in data search will be masked and placed in the data silo target location previously specified in the wizard.
If you are running a Search job on Excel files, an Excel Interchange File, or EIF (.eif extension) file is produced in the same directory as the DarkShield job. This file can be imported into the IRI CellShield Enteperise Edition (EE) product for bulk spreadsheet masking operations within Excel directly. See page 2-5 in this booklet for more information.
Below is an example of my source and target files, showing how the PII in them appear before and after a DarkShield search and masking operation:

Word Document Unprotected

Word Document Masked

Xls Document Unprotected

Xls Document Masked

JPEG Document Unprotected

JPEG Document Masked
If you would like help using this wizard to scan and/or mask data in your files, please contact your IRI representative or email darkshield@iri.com.
Format-Specific File Configuration Options
For several file types, various search/mask configuration options are available to DarkShield API users. Configuration options are not essential, however, and reasonable defaults are used in the absence of any configuration option definitions.
PDF Configuration Options
disableImageCaching: description:
Set to true if you wish to disable image caching across a document. This may help prevent out-of-memory issues when processing many unique embedded images within a document. However, it may also slow down processing if the document contains a lot of identical images (for example, a logo, or a background).
type: boolean maxMainMemoryBytes: description:
The maximum amount of memory in bytes to use when loading pages in a pdf. By default, DarkShield loads everything in memory, which speeds up processing but can cause out-of-memory issues for memory-constrained environments. If set to greater than 0, DarkShield will use a combination of memory and temporary files to iterate over the pages. Setting it to 0 will mean that only temporary files will be used.
type: integer minimum: 0 onEncodingError: description:
Define the behavior of the PDF remediator when the replacement text cannot be encoded in either the original or default fonts. By default, the original text will be redacted with a black box. The following options can be specified:
- redact Replace the original text with a black box.
- failedResult Create a failed result.
type: string enum: - redact - failedResult onTextOverflow: description:
Define the behavior of the PDF remediator when the replacement text is longer than the original. By default, the original text will be replaced with the full replacement. The following options can be specified:
- redact Replace the original text with a black box.
- replace Replace the original text with the full replacement.
- truncate Truncate the replacement text to match the original text size.
- failedResult Create a failed result.
type: string enum: - redact - replace - truncate - failedResult prettyTextReplacement: description:
Set to true to indicate that the PDF remediator should use prettyTextReplacement. This setting allows for the more seamless replacement of text in PDFs. The remediator will attempt to shift text following the replacement text by the amount of additional width produced when the replacement text is larger than the original text.
Comparatively, using the default behavior, where the replacement text width is larger than original text, there may be overlapping text at the text position. Furthermore, the default remediation (masking) operation supports fewer font types for text replacement. That said, remediation operations will be significantly slower using this configuration option compared to the default remediation behavior. Thus, use default remediation behavior if just black-box redaction is needed or if PDF has enough space between words where overlapping is unlikely to be an issue.
type: boolean setReplacement: description:
Specify a set file (a file with a list of entries with each entry on its own line) URL to select data from for use in generating data for a PDF form field.
type: array items: type: string setReplacementFields: description:
Specify the name of a form field in a PDF to insert data in from a set replacement.
type: array items: type: string setReplacementColumns: description:
Specify a zero-based index of a column to select from a set file. Set files should have columns separated by a tab. For each setReplacement entry, there should be a setReplacementColumns entry; otherwise, the default is the first column (index 0).
type: array items: type: integer minimum: 0 disableImageCaching: description:
Set to true to disable image caching across a document. This may help prevent out-of-memory issues when processing many unique embedded images within a document. However, it may also slow down processing if the document contains a lot of identical images (for example, a logo, or a background).
type: boolean disableImageProcessing: description:
Set to true to disable image processing across a document. Embedded images will not undergo Optical Character Recognition (OCR), which will increase the speed of the processing.
type: boolean maxMainMemoryBytes: description:
The maximum amount of memory in bytes to use when loading pages in a pdf. By default, DarkShield loads everything in memory, which speeds up processing but can cause out-of-memory issues for memory-constrained environments. If set to greater than 0, DarkShield will use a combination of memory and temporary files to iterate over the pages. Setting it to 0 will mean that only temporary files will be used.
type: integer minimum: 0
See https://github.com/TeamIRI/darkshield-api-demos/blob/master/test-data-generation/application-form-generation/setup.py for an example of synthesizing data into form fields of a PDF.
Image Configuration Options
boundingBoxes: description:
A list of strings representing the upper left (x1, y1) and lower right (x2, y2) corners of the bounding box. Can be either in a format of four-pixel positions in the image as whole numbers separated by spaces, or four ratios of the position in the image as a decimal between 0 and 1 separated by commas.
Examples:
Format 1: 23 100 73 114
Format 2: 0.07666666666666666,0.5238095238095238,0.7,0.6084656084656085
type: array items: type: string pattern: ^[\d,. ]+$ targetFont: description:
A string that represents the font of target text OCR will read. For credit card:
Format 1: creditCard
Format 2: OCR-A
type: string language: description:
The language parameter for the OCR engine to use to parse the image. If no language is specified, English is assumed. Multiple languages may be specified, separated by plus (‘+’) characters. The engine uses 3-character ISO 639-2 language codes.
type: string pattern: "^[a-z]{3}(\\+[a-z]{3})*$" tessConfigVariables: description:
Additional Tesseract configuration parameters that can be passed to the engine.
type: object additionalProperties: type: string tessDataPath: description:
The path to the tessdata folder containing Tesseract language models. If not specified, DarkShield will use the tessdata folder inside of the API’s install directory, or create one if it does not exist. DarkShield will attempt to download the models for the languages that were set for the File Search Context if they do not already exist. Note that the path MUST be resolvable in the server environment, not the client’s file system.
type: string useOCR: description:
Whether to use OCR or not. The default value is true. This can be set to false if only using
user-specified bounding boxes of known regions of images to significantly improve performance.
type: boolean oem: description:
OCR Engine modes
- Legacy engine only.
- Neural nets LSTM engine only.
- Legacy + LSTM engines.
- Default, based on what is available.
type: integer minimum: 1 maximum: 4 psm: description:
Page segmentation modes
- Orientation and script detection (OSD) only.
- Automatic page segmentation with OSD.
- Automatic page segmentation, but no OSD, or OCR. (not implemented)
- Fully automatic page segmentation, but no OSD. (Default)
- Assume a single column of text of variable sizes.
- Assume a single uniform block of vertically aligned text.
- Assume a single uniform block of text.
- Treat the image as a single text line.
- Treat the image as a single word.
- Treat the image as a single word in a circle.
- Treat the image as a single character.
- Sparse text. Find as much text as possible in no particular order.
- Sparse text with OSD.
- Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
type: integer minimum: 1 maximum: 14 maskingMethod: description:
The type of masking to apply to the image:
1 (default): Black Boxes.
2: Replacement of text.
Black boxes completely redact text with a black rectangle. Replacement of text will apply the masking rule associated with the search matcher that found the text to the text, and insert a generated image of the masked text into that section of the image. Specify replacement with: “replacement”. Black boxing is the default masking method if replacement is not specified.
type: string copyBackground: description:
Whether or not to try to copy the color of the background when inserting replaced text into an image with the ‘replacement’ maskingMethod set. The average RGB values will be calculated for the subregion of the image delimited by the bounding box. This can decrease performance. The default is false, which will put the text onto a white background.
type: boolean setReplacement: description:
Specify a set file (a file with a list of entries with each entry on its own line) URL to select data from for use in generating an image with the text of the entry and pasting over a bounding box region.
type: array items: type: string setReplacementColumns: description: items: type: integer minimum: 0 customFonts: description:
Specify the name of a custom font to use when replacing text in an image.
type: array items: type: string customFontFiles: description:
Specify the path of a file to load a custom font from.
type: array items: type: string
See https://github.com/TeamIRI/darkshield-api-demos/blob/master/test-data-generation/credit-card-generation/setup.py and https://github.com/TeamIRI/darkshield-api-demos/blob/master/test-data-generation/check-generation/setup.py for examples synthesizing text into images.
See https://github.com/TeamIRI/darkshield-api-demos/blob/master/pdf-image/image-text-replacement/setup.py for an example of replacing text into images, rather than redacting with a black box.
JSON Configuration Options
json: description: The configuration for reading and writing JSON documents during masking. type: object Properties: prettyPrint: description: Set to true if the JSON document should be written out in a human-readable format with proper indentation. type: boolean
See https://github.com/TeamIRI/darkshield-api-demos/blob/master/json-xml/setup.py for an example setting the prettyPrint option to true.
Fixed-Width Configuration Options
fixed-width: description: The configuration for reading and writing fixed width documents during masking. type: object properties:
columnWidths: description: Sets the length of fixed width document columns. The order in which the lengths are listed is the order in which they will be evaluated. Configuration for columnWidths can not be left empty and can not have values less than one. type: array minItems: 1 items: type: integer minimum: 1
See https://github.com/TeamIRI/darkshield-api-demos/blob/master/fixed-width/setup.py for an example setting columnWidths to the widths of columns in a fixed-width file.
Plain Text Configuration Options
text: description: The configuration for reading plaintext (text/plain) documents. If the bufferLimit and delimiter values are not set, the entire document will be read into memory. type: object properties: bufferLimit: description: The maximum size of a text block which will be searched as one unit. If no delimiter is set, then text blocks are delineated by the newline ('\\n') character. type: integer minimum: 1 delimiter: minLength: 1 type: string description: The string delimiter for delineating text blocks along with the buffer limit. If no buffer limit is set, then text blocks of up to 4096 characters will be used.
CSV Configuration Options
comment: description: Sets the comment character used to skip comment lines in CSV documents. The default is '#'. Set to '\0' in order to process comment lines as single-valued records. type: string maxLength: 1 minLength: 1 delimiter: description: Sets the delimiter to use to parse out the values in a CSV record. This option will override the delimiter detection if it is present in the config. type: string minLength: 1 delimiterDetection: description: Sets the characters that will be used during the automatic delimiter detection. The order in which the characters are listed is the order in which they will be evaluated. This option is overridden if a delimiter character is specified, in which case no detection occurs. The default delimiters are ',', '|', ';', and '\\t'. type: array minItems: 1 items: type: string maxLength: 1 minLength: 1 lineSeparator: description: Sets the line separator to use to parse records in CSV documents. By default, the parser will attempt to detect the standard OS line separators or a null terminator ('\\0'). type: string minLength: 1 maxCharsPerColumn: description: Sets the maximum number of characters that can be read as part of a value in a record. A parsing error will occur if no delimiter or line separator are detected within that character limit. The default is 4096 characters. type: integer minimum: 1 maxColumns: description: Sets the maximum number of columns that will be parsed per record. A parsing error will occur if a line separator is not encountered before the max number of columns are parsed. The default is 512 columns. type: integer minimum: 1 quote: description: Sets the quote character to indicate the start and end of a value inside a CSV record. The default is '"'. type: string maxLength: 1 minLength: 1 quoteEscape: description: Sets the escape character for the quote character in CSV documents. The default is '"'. type: string maxLength: 1 minLength: 1
DICOM Configuration Options
dicom: description: The configuration for reading and writing DICOM documents during masking. type: object properties: blackBoxes: description: Specify a list of black boxes to apply to the pixel data in the DICOM file. type: array items: $ref: '#/components/schemas/BlackBox'