Support for Star Schema
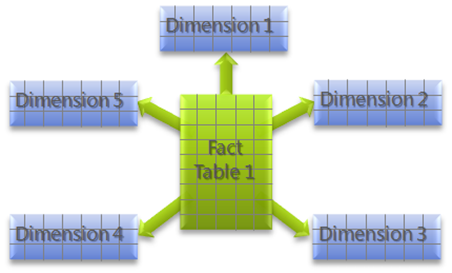
 Star schema is the simplest and most common database modelling structure used in traditional data warehouse paradigms. The schema resembles a constellation of stars — generally several bright stars (facts) surrounded by dimmer ones (dimensions) where one or more fact tables reference different dimension tables.
Star schema is the simplest and most common database modelling structure used in traditional data warehouse paradigms. The schema resembles a constellation of stars — generally several bright stars (facts) surrounded by dimmer ones (dimensions) where one or more fact tables reference different dimension tables.
Star schemas are designed to improve ease-of-understanding, and retrieval performance, by minimizing the number of tables to join when materializing a transaction.
Star Schema Characteristics
- The schema consists of a Fact table (in this case, Sale_Fact) whose foreign keys are inherited from the Dimension tables
- Each foreign key values is a concatenation of the corresponding foreign key value in the Dimension tables, and uniquely identifies individual records in the Fact table
- Many different Dimension tables may reference the same Fact, and do not usually reference any other tables.
Star Schema Benefits
| Simple Structure | The schema is easy to understand. |
| Query Performance | Queries run faster against a Star Schema (than an OLTP) because it has fewer tables and a clear join path. This design feature gives consistent query results. |
| Load Performance | This schema reduces the time required to load large batches of data into the database. The impact of load operation is reduced by defining facts and dimensions, and separating them into different tables. |
| Built-in Referential Integrity | A Star Schema is forced to maintain the referential integrity of the data by using primary andforeign keys. Primary keys in the dimension table become foreign keys in the Fact table to link each record across dimension and Fact tables. |
| Efficient Navigation through Data | A navigation through data is efficient in Star Schema because dimensions are joined through Fact tables. To construct an efficient query, you can browse a single-dimension table in order to select attribute values. |
To understand why the star schema is so popular, consider an example database from a store chain where sales-related data in a central fact table is linked by a primary key “Id” column in data, store, and product dimension tables:

The Fact_Sales table has a three-column (compound) primary key (Date_Id, Store_Id, Product_Id) and a non-primary Units_Sold column attribute that can be used in calculations. This structure allows queries on the Fact_Sales table (joined to the dimensional table) to retrieve specific information, such as the number of TVs sold by brand and country in a given year.
So what does this have to do with IRI Software?
- The Sort Control Language (SortCL) program in IRI CoSort can create and populate output file and table targets that match the layout and structure of the schema. Populating the tables can be achieved through ODBC inserts or via pre-sorted flat files fed into a database bulk load utility; e.g. a direct path load into Oracle. CoSort is a powerful data integration and staging engine for big data warehouse ETL and ELT operations.
- IRI FACT (Fast Extract) can rapidly unload very large fact (transaction) and dimension tables into flat files for archiving, migration, replication, transformation, and/or reporting purposes. SortCL can then perform SQL-equivalent queries (faster, outside the database) using sort, join, aggregation, selection, and custom layout commands to produce detail and summary reports.
- IRI FieldShield can apply common encryption functions across linked fields in one or more tables in the schema … preserving data formats, recoverability, and referential integrity at the same time.
- IRI RowGen can produce and load structurally and referentially correct test data in both star schema fact and dimension tables, pre-sorted over the primary key value. Any number of rows can be generated for the tables individually, with column values reflecting the appearance and frequency distributions of (but without coming from unsafe or inadequate) production data.
- The IRI Voracity ETL platform, which supports all of the above, also creates star schema E-R diagrams, converts to and from star schema, and uses it in data integration (ETL), lineage, quality, and replication jobs, tpo.
Contact voracity@iri.com if you have any questions.