Unmasking the HL7 Data Standard
In this series of articles, we will describe the semi-structured HL7 file format used in many healthcare industry data storage and processing settings, and show how you can rapidly transform and mask large volumes of HL7 XML messages without writing code.
This first article introduces the HL7 standard and explains how HL7 messages are structured with an example. The next article will cover parsing and structuring this data with Flexter Data Liberator and seamlessly processing (transform, de-identify, cleanse, report on, etc.) the results in the IRI Voracity platform. Note that for PHI data masking purposes, it is also possible to process HL7 and X12 messages in unstructured text or XML files using IRI DarkShield directly, without pre-parsing or other processing.
The HL7 Industry Data Standard
Health Level 7 (HL7) is the primary data standard for the healthcare industry worldwide. HL7 allows clinical systems to speak the same language when exchanging data as messages.
HL7 started in 1987 when an international group of experts created a first version of the standard. Volunteers founded the not-for-profit “Health Level Seven International” consortium and declared HL7 2.1 to be the first usable version of the standard in 1990.
The standard was widely adopted after the ANSI-compliant v2.3 was released. All minor releases of HL7 2.x are backward compatible, which made it hard to evolve the standard. As a result, HL7 v3 was released and exists alongside v2.x. However, adoption of v3 has been slow, and the vast majority of implementations are still based on version 2.x. HL7 is also ISO-compliant.
HL7 XML Encoding
HL7 messages can either be encoded in EDI or XML. At first, only EDI was used as a serialization mechanism. However, XML has various advantages over EDI. It is more widely adopted than EDI, and there are a lot of tools, such as Flexter Data Liberator, to efficiently process XML messages.
XML messages come with properly defined schema files called XSDs, which are widely used to implement industry data standards. Here is an excellent guide from the HL7 website on how to encode HL7 messages in XML. It also shows examples of how the messages differ from EDI.
HL7 XML Message Structure
HL7 Message Types
Before we process HL7 XML files with Flexter Data Liberator, let’s have a look at how HL7 messages are structured.
First, there are different message types, each representing a business process of the overall standard. The most popular message types are for patient administration and orders.
Each message type is represented by a code. For patient administration, this code is ADT, which stands for Admission, Discharge, and Transfer. Another popular message type is order entries. One of the message codes for orders is ORU.
If you want to learn more about the message types and their implementation, see the HL7 messaging standard specifications from the HL7 website. The v2.3.1 HL7 specification is over 1,000 pages and can be downloaded here (registration required).
HL7 Trigger Events
Each message type is split further into so-called trigger events. A trigger event correlates to an event in the real world; e.g., admission of a patient to a hospital or observation messages.
HL7 XML Sample Files
You can also download HL7 XML examples for ADT and ORU from the HL7 website.
The sample HL7 XML message below is of message type Observation Reporting (ORU), and corresponds to trigger event R01. What does this mean? ORU is an observation message used to transmit lab results. The R01 trigger event instructs the receiving system to create a new observation report.
![]()
Segments
Each HL7 XML file is further split into segments. In our sample XML file, we have the segments for Patient (PID), Patient Observation Request (OBR), and Patient Observation (OBX).

Sequences
Each segment is further split into one or more mandatory or optional sequence numbers. Here is an example for PID:
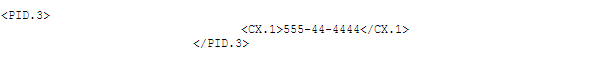
In the above PID element, we are dealing with PID sequence number 3. We can look up what sequence 3 stands for in the specification.
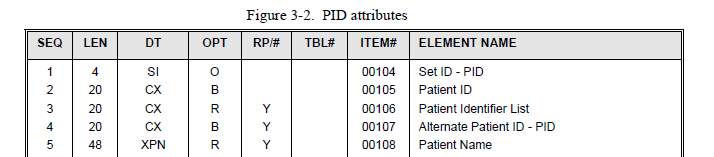
We now know from the lookup table that sequence 3 is the Patient Identifier List. Apart from the name of the element, the above table also tells us if a sequence is optional, backward compatible, or required (column OPT), plus other pieces of information, like the length of the field.
Data Types
What about XPN.1 (<CX.1>555-44-4444</CX.1>) then, which is the next element in the hierarchy?

This is a so-called data type. In HL7, there are simple and complex data types. An example of a simple data type is TS, which is a timestamp. An example of a complex data type is XPN, which stands for Extended Person Name. Codes for data types can be looked up in the specification.

HL7V 2.3.1 page 2-60
Note: Instead of writing out the full name for each code, element names are abbreviated to keep the size of the XML files small for faster network transport and processing.
Parsing HL7 XML Files
Now that we have some background knowledge on the HL7 standard and understand how HL7 XML messages are structured, we can process them into a relational format.
The next article shows how the enterprise version of Flexter Data Liberator parses and structures the XML examples from the HL7 website mentioned in my introductory article on HL7, and how IRI Voracity seamlessly processes and protects the results in relational database tables.










