
Joining Flat-File & RDB Data: Textual ETL (Part 2)
Introduction
This article demonstrates the Voracity user’s ability to join values in a flat-file file to those in an RDB (Relational Database) table to provide meaningful information. It is the continuation of this article on preparing unstructured data for integration with structured data and the standard technologies (like an Oracle database or JSON file) that support them.
As shown in that first article, the flat file was created by SortCL data transposition scripts acting on a delimited IRI DarkShield log file. That DarkShield log (optionally) held PII values along with file-specific metadata from a search through multiple unstructured data sources. The SortCL jobs pivoted the log file into a new row-column structure organized by data class for easier use.
Neither the original log file nor the pivoted flat file with the PII provides discernibly meaningful information about any particular individual beyond the email addresses or names in them. This is because all DarkShield searches log PII found in unstructured sources chronologically. And by definition, there is no structure to lend associations to the PII elements found anyway.
Thus for those interested in learning more about, or making use of, unstructured data like the PII in this case, an association to this data must be (re)established. To do that in this case, we pick one of the PII elements from the transposed log file – in the example below, the email address – and join it to a structured source (e.g., a database table) that may hold the same email address along with actually identifying, or otherwise meaningful, information about that same person.
Why Does this Matter?
What is a use case for this kind of capability? Consider a non-descript email address that DarkShield found in a PDF complaint describing criminal activity, or an account number found in a chat log or call recording. How about clinical notes naming a patient and their symptoms with no link to care or trial resources? Unfortunately, such data is often just archived and untapped.
Instead, consider what can happen when those values are extracted and combined with traditional sources of data in sequential files, semi-structured EDI documents, or relational databases? In the cases above, a perpetrator could be identified, an account holder protected, and a patient treatment record made more holistic.
Heretofore, addressing this data combination challenge has been largely manual, and most such efforts would prove unfruitful. The example in this article therefore serves two purposes:
1. To complete the textual ETL example in the first article by showing how the disassociated PII (email addresses) discovered by DarkShield in Voracity can be joined to create useful information about any emails for which there is a match in the join; and,
2. To demonstrate how to create and run a join operation in the IRI CoSort product or Voracity ETL platform using the SortCL job script and program common to both.
Textual Data Integration Example
This sample use case will use real data in a structured database to identify the owner of matching email addresses discovered in a PII search job that DarkShield performed across unstructured data sources. In the first article, we transposed the DarkShield log file into a disassociated but formatted report of discovered PII:
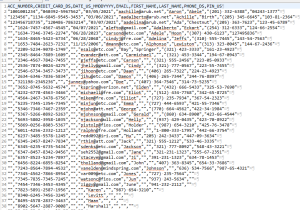
Looking across these restructured rows, there is no relationship between any of the elements. But in the relational database fact table below, there are (note matches of names with emails):
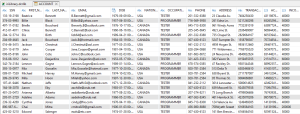
To identify the real owner of the DarkShield-discovered email address using the real database table above, perform a join on the Email field between the CSV file and the table. To build that job, run a fit-for-purpose Join job wizard from the CoSort menu, or an ETL Join in Voracity, in the IRI Workbench GUI.
The join job wizard in Workbench starts with specifying the name and location of the job script:
In the Data Source screen that comes next, specify the CSV file (transposed after a DarkShield search per the prior article), and the existing database fact table. In this case, that table, called ACCOUNT, is in an Oracle schema called SCOTT.
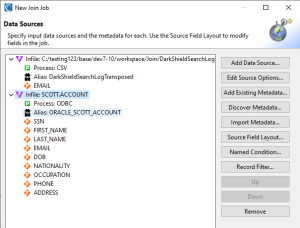
From the CSV file, only pull in the EMAIL field to join and then map to output. From my table, specify both the EMAIL field for the join, and all other columns of interest associated with any email addresses that may match some in my file. More specifically, map out the values in the SSN, FIRST_NAME, LAST_NAME, DOB, NATIONALITY, OCCUPATION, PHONE, and ADDRESS columns.
Also required with each source is its /FIELD metadata layout in SortCL Data Definition File (DDF) syntax. We can either add them from an existing DDF file, or auto-generate and incorporate the /FIELD definitions through the ‘Discover Metadata …’ option.
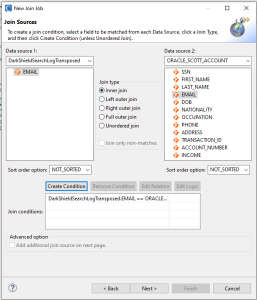
Next is choosing and defining the join key. In this case the join key is the EMAIL field. The statement syntax will need to reflect an inner join (match) for the EMAIL field in both the file and the table:
/JOIN NOT_SORTED DarkShieldSearchLogTransposed NOT_SORTED ORACLE_SCOTT_ACCOUNT WHERE DARKSHIELDSEARCHLOGTRANSPOSED.EMAIL == ORACLE_SCOTT_ACCOUNT.EMAIL
This function can be constructed graphically on the next page of the wizard by selecting EMAIL on both sides of the join:
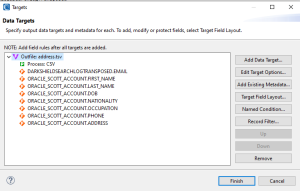
The next and final page of the wizard is where the target file format and field layouts are defined and, if desired, further formatting and transformations. In this case, the joined rows will be kept in a Tab-Separated Values (TSV) file with no further functions performed on the output values, such as aggregation, masking, or data type conversion.
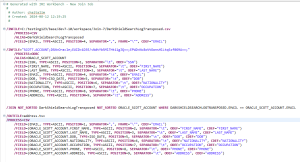
Once we finish the wizard, a job script like this is built automatically from what was specified:
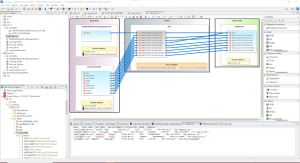
From the job script above, the transform mapping (ETL) diagram shown below is produced where the two sources, the email values from the file are matched to email values in the table. The table contains the other attributes of interest that will be written to output.
The output fields are then written in tab-delimited format. The CSV process type defined in the output phase of the job script will generate a header record in the output file.
When the join is run, this output report is produced that reveals the identity of the people in the table whose email addresses matched those which DarkShield had found in its search through multiple unstructured data sources:

If you have any questions or are interested in ETL, textual or otherwise, please get in touch with voracity@iri.com.










