
A Data Mesh Approach to Consider
Abstract: Adopting a data mesh approach represents a contemporary solution to the challenges faced by traditional centralized data management systems. This article summarizes what data mesh architecture is about, and how you can leverage its key benefits using the IRI Voracity platform.
What Is Data Mesh and Why Should You Care?
The core principles of data mesh include domain-oriented decentralized data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. These principles empower individual business units to manage their own data, ensuring interoperability and governance across the organization.
The benefits of a data mesh approach are significant. It can improve scalability, agility, and data quality. Decentralizing data ownership reduces bottlenecks and speeds up decision-making.
Treating data as a product encourages data producers to deliver high-quality, reliable data. The self-serve data infrastructure allows teams to access and use data without relying on a central IT department, fostering innovation and collaboration.
However, implementing a data mesh also comes with challenges. Organizations need to invest in the right tools and technologies to support decentralized data management and ensure proper governance.
Cultural and organizational shifts are also necessary to transition from a centralized to a decentralized approach. Strong leadership and clear communication are crucial for driving the successful adoption of a data mesh.
In short, adopting a data mesh approach can be complex, the potential benefits make it a worthwhile investment for organizations looking to modernize their data architecture. By embracing the principles of data mesh, companies can achieve greater flexibility, efficiency, and innovation in their data management practices.
The IRI Approach to Data Mesh
The IRI Voracity data management platform has the ability to combine data discovery, integration, migration, governance, and analytics. Because Voracity maps data between multiple source and target formats and silos, it’s a platform you may wish to consider using at the center of your data mesh.
The data mesh is actually just a more recent paradigmatic manifestation of other Voracity-supported data integration architectures. Voracity can be used in ways not dissimilar from a Logical Data Warehouse or Production Analytic Platform. What distinguishes a data mesh primarily are its characteristics of: 1) Domain-driven ownership/design, 2) Data as a product, 3) Self-service data infrastructure, and 4) Federated computational governance.
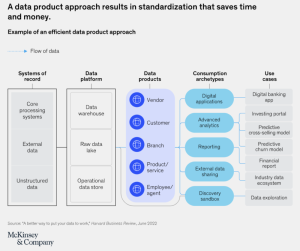
As described in DBTA best practices issues around Data Integration and Governance, Voracity can serve as a Data Infrastructure and Federated Governance platform that supports domain-driven design. If you review our Big Data Packaging page, you’ll see that the core idea of Voracity as a data mesh platform is the same – to integrate and govern data from disparate sources to make informational output, or data products, fit for data science use (and re-use).
In a data mesh, you wind up with something akin to data marts, and in Voracity, you can – without a data warehouse team – produce immediate data products or reports, too. Integration, cleansing, masking, and reporting are all same-job, same-pass affairs. You can quickly wrangle your own data products that contain trustworthy, business-formatted subsets (or formatted reports) with clean, anonymous, and de-duplicated data inside.
Voracity follows A Data Mesh Approach to Data Warehousing, as described in this 2021 Alexis Mackenzie article in Towards Data Science – from FAIR principles 1 supported by SortCL data definition language files cataloging structured source metadata to using non-competing, real-time read replicas supported by the IRI Ripcurrent module.
Voracity delivers several Federated Governance platform features recognized in data mesh architecture, including: data search, profiling, classification, masking and cleansing (quality), plus basic cataloging and lineage. A number of data observability and access control capabilities are also included.
Voracity Data Infrastructure platform features include: support for polyglot source and target data stores, pipeline orchestration, CI/CD integration, data product versioning (via Git), PII and access credential encryption, and big data transformation performance that scales vertically or horizontally. A number of graphical self-service data engineering and democratization features are also available through the DataSwitch web front-end.
Beyond the functionality Voracity embeds, another key consideration is how it addresses a common problem with data meshes: a lack of clarity around data ownership. When different people are looking at different data products to find answers to the same quantitative question, they will get different answers, and usually after data has been replicated too many times.
A properly designed data mesh can clarify data ownership and thus an authority within the company for engineering and business teams to consult on things like: common data definitions, data discrepancies, inter-domain integration points, and reducing unnecessary data normalization steps.
The aforementioned FAIR metadata in Voracity can help align data producers and consumers. Data sources and accesses are registered in the IRI Workbench design IDE and readily identified in job scripts. Voracity data-product projects with those artifacts can be shared, compared, and discussed from a common repository like Git.
This framework in Voracity is flexible and easy enough to create small test projects quickly. By conducting a variety of POCs within your company can find the best ways to build governed, efficient data products.
For more information, please visit www.iri.com/voracity or email voracity@iri.com.
- FAIR data is characterized by its findability, accessibility, interoperability, and reusability.










