
IRI Product Nomenclature & Architecture
The names of IRI software products and how they run have at times been a source of mystery, or even confusion, to the uninitiated. This article spells out the pieces and clarifies their interplay, providing a quick primer for prospective users, partners, and new industry analysts.
Where it All Began
It began with IRI CoSort in 1978, the big data sorting, transformation, and reporting utility for Unix and Windows still in wide use today. Prior to CoSort, this first IRI product was called CO-SORT, COSORT, and CoSORT, in that order.
![]()
In 1992, IRI added the Sort Control Language (SortCL) data definition syntax and manipulation program to the other utilities and APIs in the CoSort package. Today, SortCL is the most widely used, and feature-packed UI in the CoSort package.
SortCL scripts define, and the sortcl program runs, the jobs that perform and combine many common data movement and mapping tasks that CoSort users need to run. SortCL is not only a simple 4GL to learn, read, and modify, but it is also supported through an API (called sortcl_routine), and graphically in the IRI Workbench IDE, built on Eclipse.
As SortCL functionality expanded, it outgrew the traditional CoSort market for sort migrations and BI/DW acceleration. Today, the SortCL executable is not only the engine running most CoSort jobs, but it’s the beating heart of several spin-off products, illustrated here:

CoSort / SortCL Spin-Off Products
Specifically, the same SortCL engine and compatible job scripts — usually designed and often managed from IRI Workbench, process structured data sources in:
- IRI FieldShield for data masking
- IRI RowGen for test data synthesis and database subsetting
- IRI NextForm for data and database conversion and replication and, the
- IRI Voracity data management platform jobs, which include those in CoSort and the products linked above, plus additional front-ended capabilities through the common Workbench GUI, like:
- Data discovery (profiling, classification, and search)
- Data warehouse ETL, CDC, and SDC
- Data Vault 2.0 migration and prototyping
- Data quality (validation, cleansing, homogenization)
- Analytics or data wrangling for Splunk and KNIME, and other BI tools via handoff
- IRI Ripcurrent, for real-time DB replication, incremental masking, and schema change notification
IRI DarkShield is not powered by SortCL, since it’s designed to search and mask a range of disparate data sources (semi- and unstructured too). But DarkShield is also front-ended in IRI Worbench and included in the Voracity platform.
Another way to look at the product hierarchy is this way:
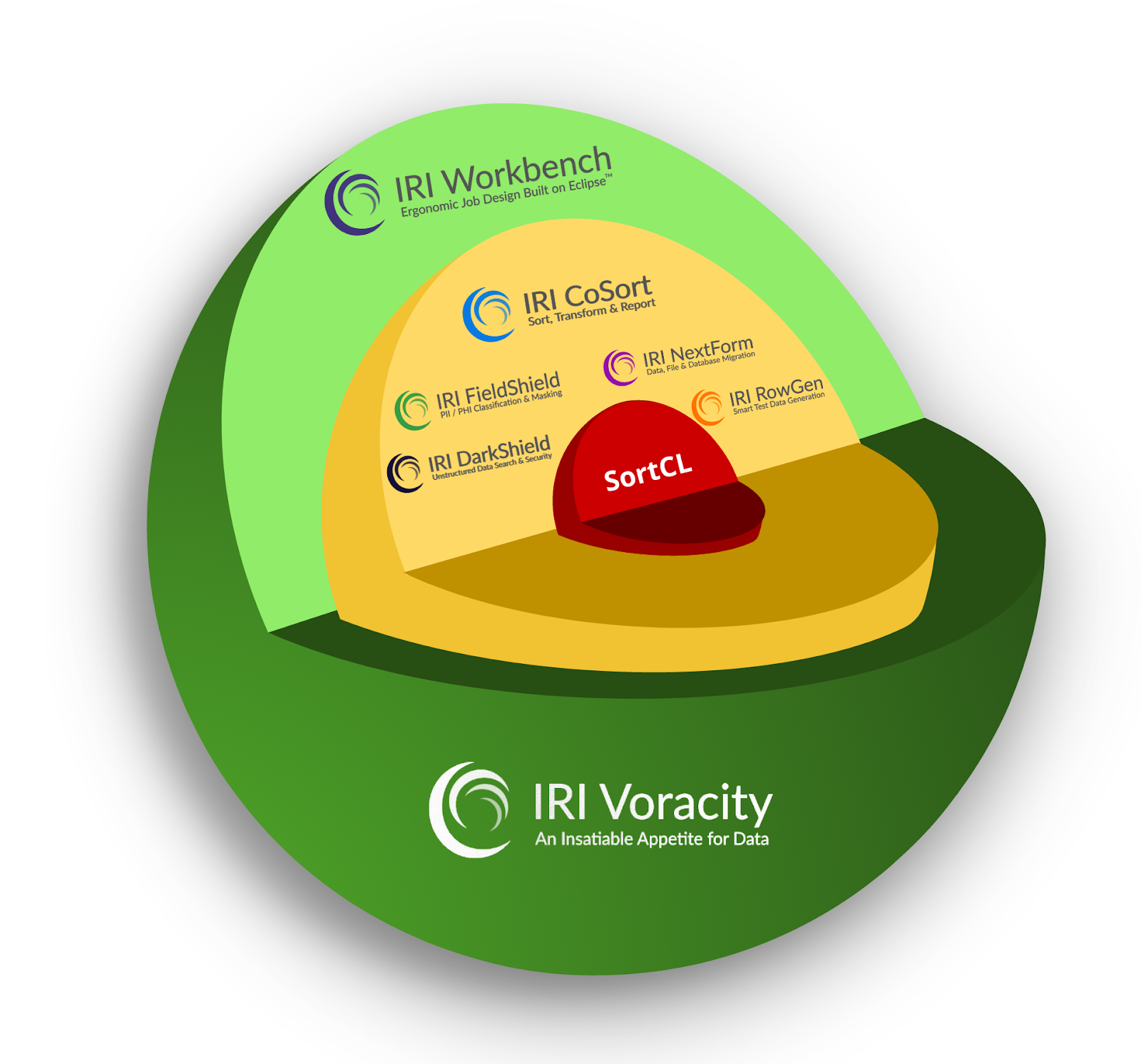
where the Workbench IDE is where all IRI product jobs are designed — including those additional features supported in Voracity.
A Frequently Asked Question
Since SortCL started with CoSort, and is common to all these products, does this mean I can use CoSort or another product above to do what the other products do, too?
The answer is yes and no. Yes, you have SortCL, and can in theory get some of the same work done that another SortCL-compatible IRI product is meant to perform. But it would be more difficult and represents a production risk. IRI only provides documentation and support for the tasks best associated with your licensed IRI product(s).
Therefore, crossover capability is limited in practice. Nevertheless, combinatory functionality is common in many cases (like a sorted DB subset), and in Voracity, multi-task, multi-step use cases (like incremental mapping, masking, cleansing, and reformatting) are highly efficient and fully supported.

SortCL is the default engine in all IRI Voracity CDC, ETL, CDC, cleansing, reconciliation, subsetting, PII masking, test data synthesis, conversion, reformatting, wrangling, analytics, and reporting jobs.
Runtime Architecture
Now that you know the names of the products, let’s cover how they interrelate and deploy.
IRI software usually operates in a client/server model, where SortCL-compatible jobs are defined in a front-end editing environment like IRI Workbench or other text editor, or via the IRI API. Those jobs usually run in the SortCL back-end program on Linux, Unix or Windows (physical or virtual) machines, on-premise or in the cloud:
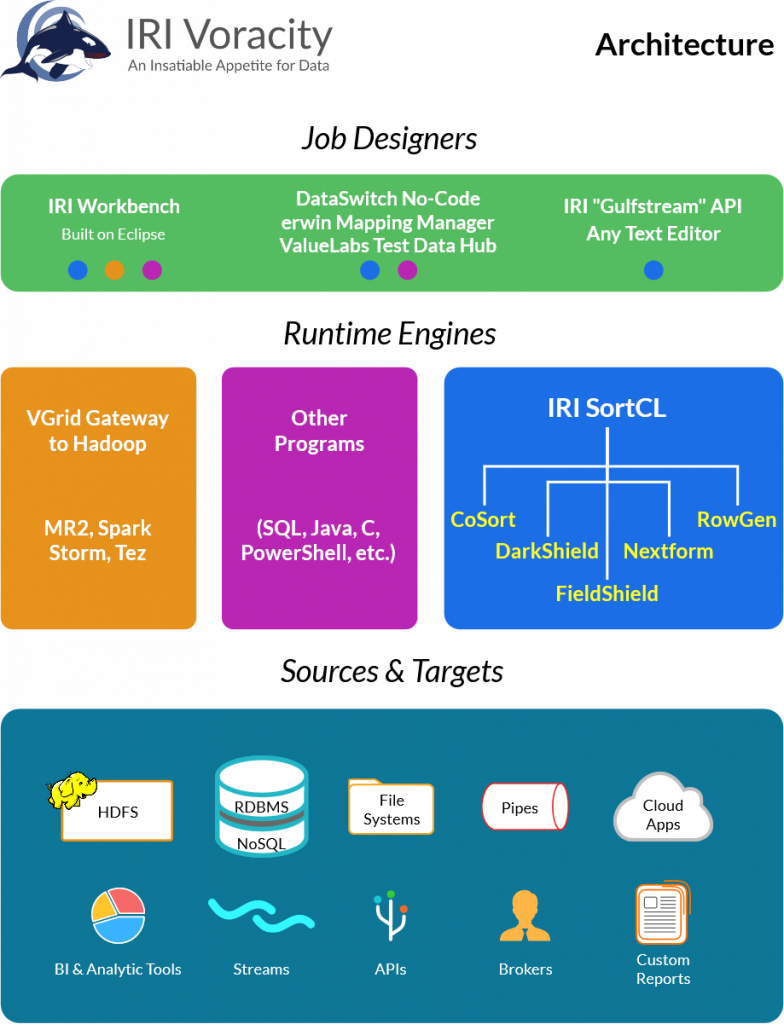
Some jobs scripted in SortCL syntax can also run without modification directly in Map Reduce 2, Spark, Spark Stream, Story, or Tez for licensees of the Voracity Grid (VGrid) edition for Hadoop.
Note however that unlike many other ETL and data masking programs, there is no CoSort server where SortCL must run or be managed centrally. The lightweight SortCL executable can run anywhere from a Raspberry Pi to a z/Linux mainframe.
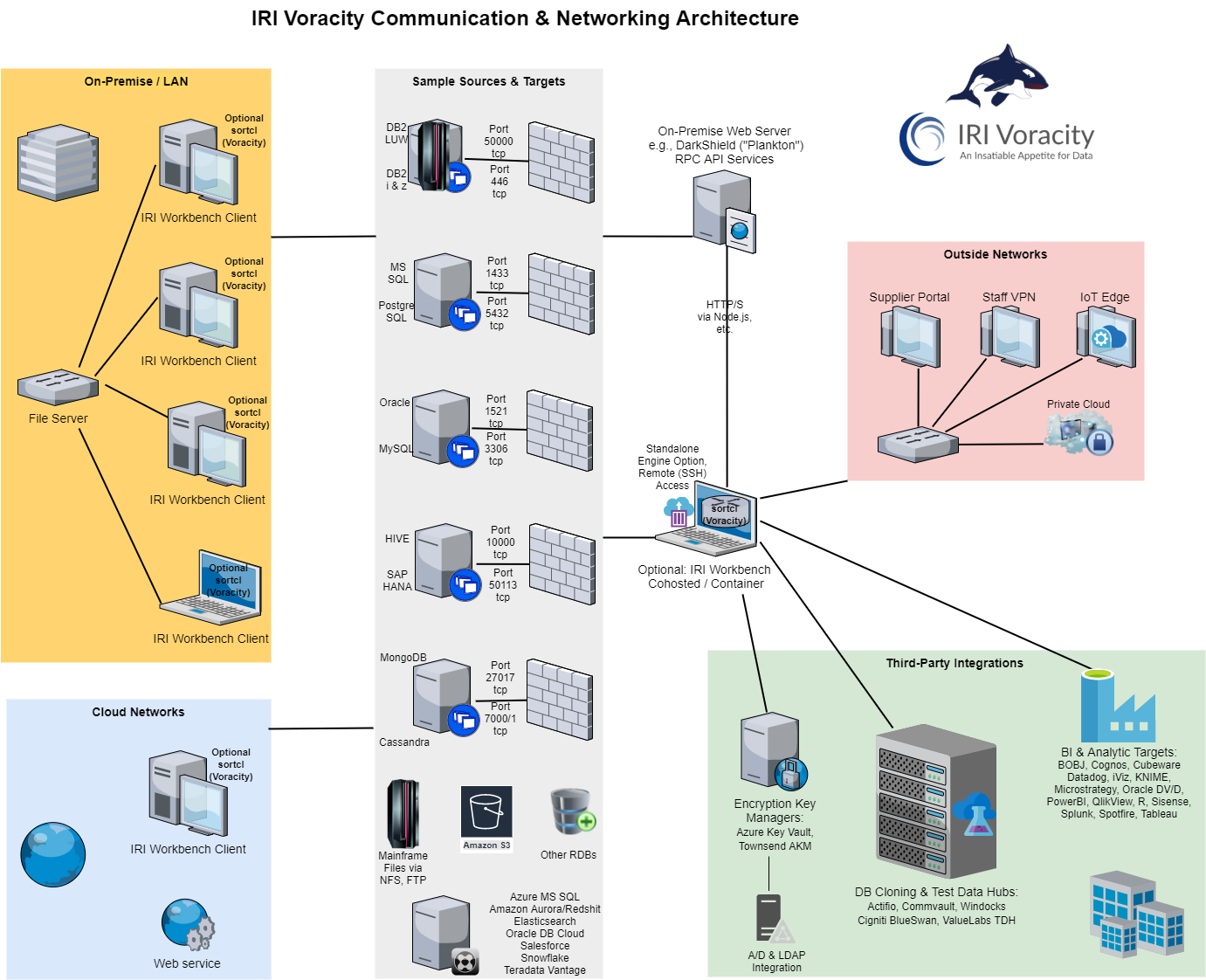
It is therefore common, per the diagram above, for sites to have test and QA SortCL instances installed on developer laptops running IRI Workbench, as well as on centralized file or database servers to optimize performance. This FAQ covers the question of where to license SortCL in the context of IRI data masking products, for example, and how to factor its costs accordingly.
If you have any questions about which IRI product you need, or how to best deploy it on the hardware you have (or plan to provision), please contact your IRI representative.










