On the Importance of Metadata
Background
Lines of business do not think in terms of metadata per se. Users want to know what information is available, and where it is. They want to know if the data is reliable, protected, who’s using it, where it came from and how it’s been changed.
The best way this information about data is organized is through a metadata layer. Metadata defines the layout and lineage of technical and business data, and master data, in the enterprise. The Kimball definitions provided in the data warehouse section of this Wikipedia article explain three main types of metadata. I refer mainly to business metadata here.
Challenges
Of course, different systems and applications have their own metadata structures. Flat files have their own formats and repository structures (e.g. COBOL copybook). Databases, BI, and ETL tools use their own syntax and semantics — many of which are cryptic and some of which are hidden. This represents the kind of metadata management challenge we can call complexity.
Meanwhile, the volume of metadata will only grow as the number of files (e.g. in Hadoop clusters) and tables increase, and as data architects and data scientists require more provenance information about data before and after it gets mapped (transformed).
Beyond the technical and semantic characteristics of data are administrative characteristics. For example, metadata can also now be used to classify information according to data security levels. So while data governance requires an understanding of data sources for reliability, regulatory governance requires the understanding for privacy law compliance. The rules that apply to the use or protection of data should be part of a modern metadata management infrastructure.
Operations
Business metadata is the key to accessing and using operational data. You need to understand what kind of data you have in order to effectively leverage it. Not understanding the information can lead to bad business decisions.
Metadata is key to effectively building and maintaining effective operational reporting systems. It’s so important to discover, understand and steward data. Unlocking business metadata and allowing it to be searched enables customization and extension of data sources and descriptions, and optimizes the discovery and use of information in reports … again, so better decisions can be made.
It should not matter which tool you are using for BI … better to have a common view and understanding of all data regardless of the storage and reporting platform. Removing the technical restraints of their semantic models can be of great value to the enterprise because more people will be able to make use of the data.
Solutions
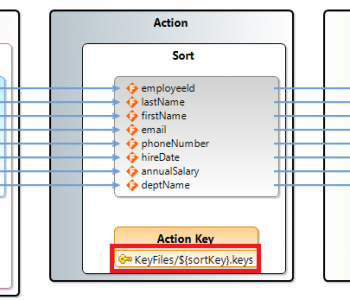
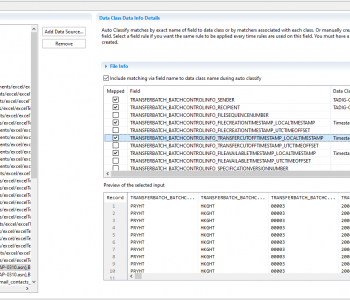
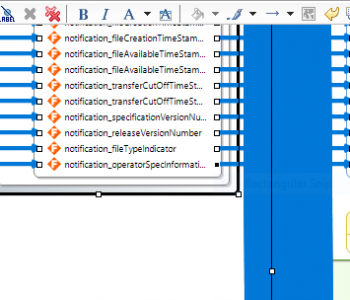
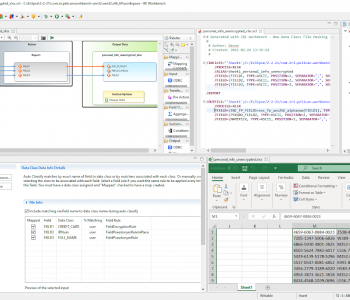
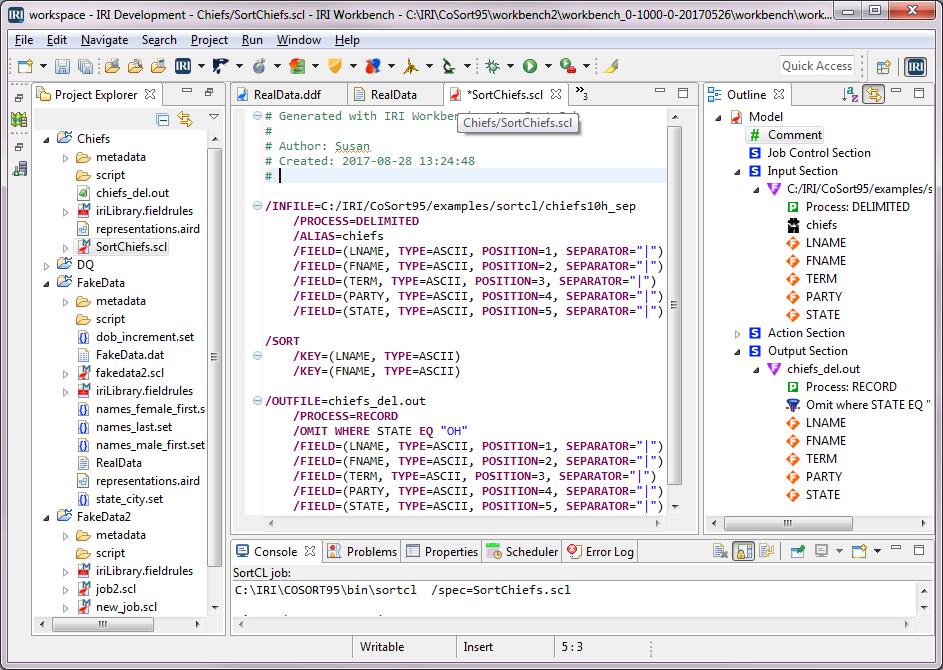
IRI software provides a simple, shareable metadata infrastructure and Eclipse GUI that both unifies the layouts of disparate data and supports the lineage and impact analysis of changes through already-familiar version control systems. There are in fact many advantages to IRI’s data definition file (DDF) metadata repositories.
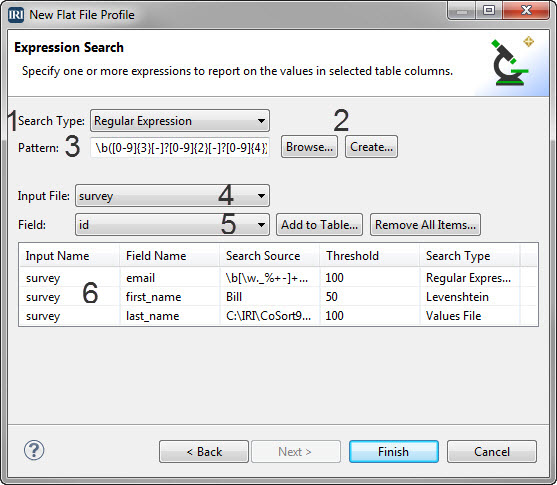
One advantage is having the option to tie DDFs to sources in the DDF itself or just in the job script which uses it. Either way, you can leave the source data in place, and access it when and where you need it. Other advantages are metadata browsing and sharing, version control, keyword search for lineage analysis, metadata security and bulk modification.
More advantages to IRI’s metadata approach are on the web site: