 Data Migration
Data Migration
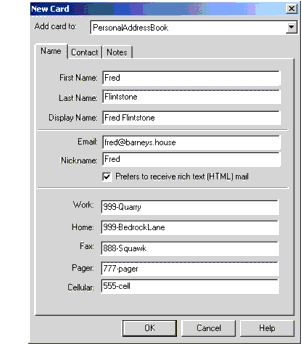
Examining the LDIF File Format
LDIF (Data Interchange Format) is a standard, plain text-based file format representing LDAP (Lightweight Directory Access Protocol) data for address books, spreadsheets and other structured data forms that can be easily manipulated with a text editor. Read More








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}