
Generating Test Data in PDF and Image Files
IRI DarkShield has always had the ability to search through and mask Personally Identifiable Information (PII) and other sensitive data in unstructured sources like PDF documents and image files. Now DarkShield can also work with IRI RowGen to generate and insert test data in those formats, too, on-premise or in the cloud.
 This capability enables developers and testers of applications that process or otherwise manage these sources of data to work with realistic, but safe/artificial samples in DevOps, etc. It does not enable fraudulent document or image creation due to material differences in the background (appearance) and nature (randomization) of the test values, per the samples shown.
This capability enables developers and testers of applications that process or otherwise manage these sources of data to work with realistic, but safe/artificial samples in DevOps, etc. It does not enable fraudulent document or image creation due to material differences in the background (appearance) and nature (randomization) of the test values, per the samples shown.
This article will explain the new functionality in the DarkShield-Files API which enables this capability, and provide some examples of creating test data in PDFs and images.
Generating Test Data in PDFs
In PDFs, values have always been able to be replaced with a consistent or random pseudonym replacement from a set file (dictionary lookup file) of test values. However, now form fields in PDFs can be populated from scratch with set-file data values, too.
Multi-column set files can be used as well, and any references between values within a row will be kept. What this means is that if a multi-column set file with related values such as city, state and zip code are used, their relationships can be maintained in a realistic fashion.
A form field is referenced with the field’s name, which can be viewed through an application like Adobe Acrobat Reader, or dispensed through a new utility application called pdflist provided in the bin folder of a plankton distribution starting with version 1.4.0.
Form fields can be filled out in a similar way to user-specified bounding boxes in images. In the case of form fields in PDFs, the field is referenced by a name, which defines where to put the data and is akin to specifying the coordinates of a bounding box in the case of an image.
The field can either have its value searched and replaced based on masking rules, or a random value can be pulled from a set file. If specifying fields to be filled with different columns from the same set file, relationships are preserved (i.e. a set file with zip codes, cities, and states in separate columns will select the correct city and state that goes with a zip code).
I have set up a file mask context with several configuration options corresponding to the fields I want to generate test data for, and what type of data I want to draw from for each field.

setReplacement specifies a URL containing a tab-delimited file called a ‘set’ file. setReplacementColumns specifies the column to take from each set file (starting from index 0). The default behavior is to take the first column if this option is not set.
setReplacementFields specifies the name of each field in a PDF form to produce data from the file specified in setReplacement at the same index. onTextOverflow being set to replace allows for text in a PDF to be replaced with text of longer length, as can be the case in pseudonymization.
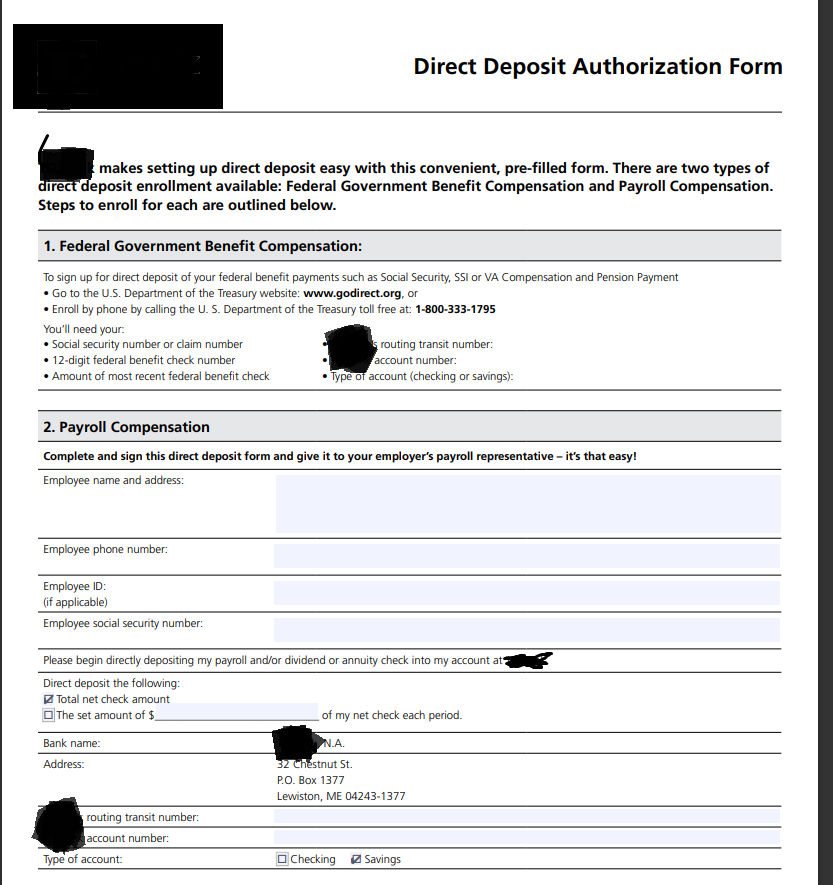 Original PDF form
Original PDF form
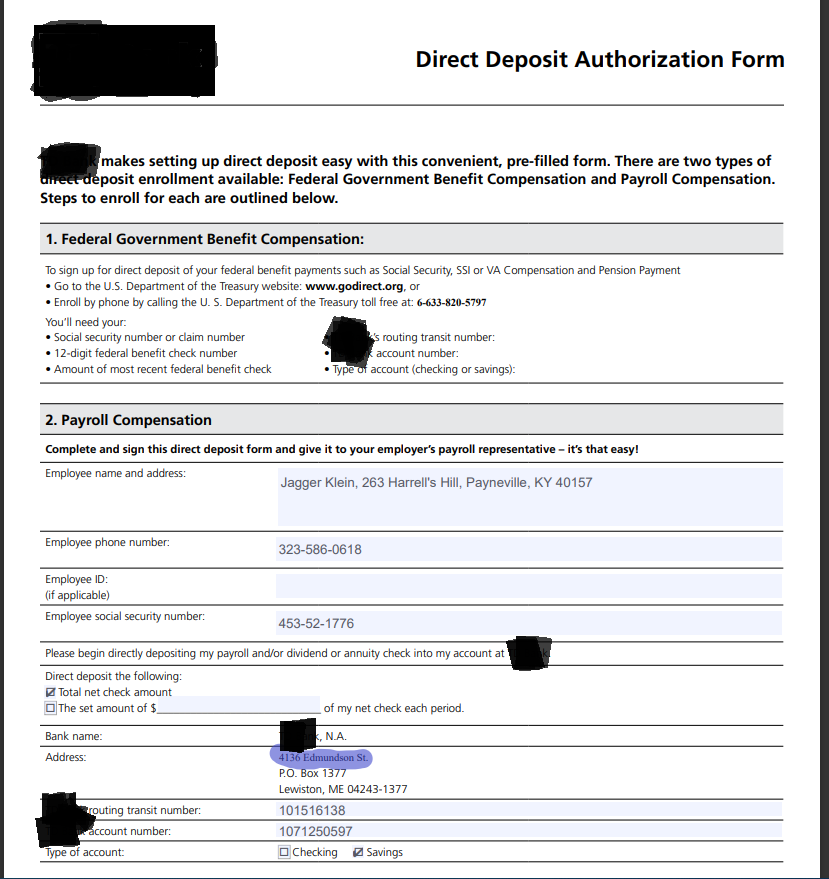 Resulting PDF returned from the DarkShield API
Resulting PDF returned from the DarkShield API
Employee name and address, employee phone number, employee social security number, address, routing number, and account number have been freshly generated. Note that the form fields were populated from scratch, and the fixed address was replaced with another address from a set file (shown highlighted).
Generating Test Data in Images
As for images, text can be generated into a bounding box area to replace either existing text that was found through OCR and deemed as sensitive by the search matchers that have been set up, or directly into a user-specified bounding box region. This new functionality for generating test images also offers the ability to try to copy the background color based on the most common RGB values in the bounding box region.
Background color is specified as a file configuration option in a file mask context, which also includes other new options such as UseOCR, setReplacement, setReplacementColumns, and maskingMethod. UseOCR can be set to false to greatly improve performance if only using user-specified bounding boxes. On the other hand, if using OCR, maskingMethod specifies what should be done with the text that was searched and found as sensitive.
Setting to replacement will allow for text to be replaced based on the masking rule associated with the search matcher. This text will be inserted into the original text area as generated text. The default option (and previously only option) if replacement is NOT specified is to redact the original text with a black box.
setReplacement specifies the set files to be used for each user-specified bounding box to generate text in an image. setReplacementColumns specifies the column of the set file to pull from, and should be in the same order as the setReplacement and boundingBoxes parameters.
To get the coordinates to use for a user-specified bounding box, it is easiest currently to use the bounding box search matcher in IRI Workbench. This allows a user to select an image, view it, and draw the bounding box.
The coordinates are then output as the details of the search matcher. These coordinates can be copied and used to specify bounding boxes to the API through the file mask configuration. Multiple bounding boxes can be specified, and there is no restriction on the number of bounding boxes that can be specified.
Test Data in Check Images
The demo, available on GitHub, demonstrates generating check images, replacing the information in the top left corner (name, address, city, state, and zip) with test data. The routing number and account number have also been generated on top of the base image.
Additional bounding box redactions could have been specified for other areas of the check, like the payee, bank logo, and account holder’s signature.
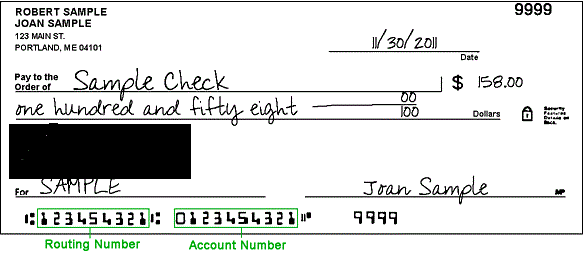 Original check image #1
Original check image #1
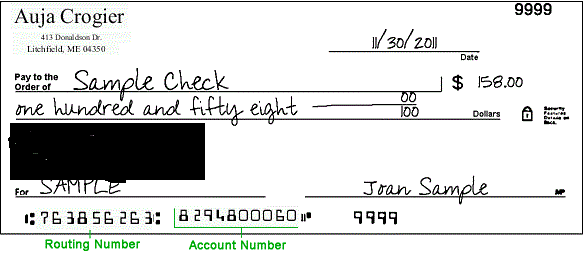 Test data image #1 – MICR font used for test numbers
Test data image #1 – MICR font used for test numbers
 Original check image #2
Original check image #2
 Test data image #2 – Different backgrounds result in bounding box color differences, too.
Test data image #2 – Different backgrounds result in bounding box color differences, too.
Test Data in a Driver’s License
In this example, I defined some bounding boxes to redact the two locations where the face is shown in the image. In addition, I set the masking method to replacement, which will replace text that is found in an image and matched with a search matcher.
The search matcher matches some common names and cities that I have defined in a set file. The masking rule is to pseudonymize the original value with a replacement value from the same two-column set file.
Names and cities are consistently pseudonymized to an alternate value based on the mappings in the set file. In this case Harrisburg was replaced with Pittsburgh because it was another city in PA.
 Original image
Original image
 Resulting image from DarkShield Files API with selected new data and redacted photos
Resulting image from DarkShield Files API with selected new data and redacted photos
Test Data in a Credit Card Image
In this example, the numbers in an image of a credit card are replaced with synthetic numbers using an OCR-A font that credit card numbers often utilize.
These numbers are taken from a set file that can be produced with IRI RowGen using the ccn_gen function. That function takes optional arguments of a specific credit card type (or all major types) and a separator between each group of numbers.
See the RowGen script below that I used to generate the set file of synthetic credit card numbers. It is generating VISA credit card numbers with a space in between each group of numbers:

Here are the original and synthetic credit card images, with no change to the name or expiration date:
 Original image
Original image
 Synthesized image
Synthesized image
Note that invalid card numbers can be created as well, and it is possible in glue code to imprint a watermark to remind viewers as to the artificial, test nature of the image.
Mass Test Image Creation
Generating test images in bulk uses a combination of IRI DarkShield, IRI RowGen, and calls to the DarkShield API through glue code. RowGen can synthesize set files to use for generating test data in images and PDFs with DarkShield.
I used RowGen to merge existing data from set files that ship with IRI Workbench and some names that I had extracted from the most common baby names in the United States to create a single, multi-column set file with first name, address, city, state, zip, and phone number.
Since the data I had gotten for common last names was in all upper case, I also cleansed it by using the toproper function, which puts a name into ‘proper case’ to make it more realistic for insertion into an image. This involves making the first letter in name uppercase, and the rest of the letters lowercase, except for certain cases like ‘McDonald’.
Here is the script I created in the IRI Workbench GUI for RowGen to generate that test file with 1000 rows and 7 columns.

I also generated set files for account number and routing number with RowGen by simply generating a field with the data type of digit and the equivalent realistic size (number of digits).
These set files are referenced in the DarkShield API by specifying configuration options in a file mask context. The set file URL can be either a local file URL or an Internet URL.
Here is an example of Python glue code used to set up contexts to the DarkShield API to use in generating test data for check images. OCR is being disabled as a configuration option in the file search context to greatly improve speed, since the data being dropped into the image is at a consistent location.

Also shown in this image is the ability to specify a custom font with the customFont image masking configuration option. The default font for replacing text in images is Times New Roman if no custom font is specified.
A custom font can also be loaded from a file by specifying the path to the file in the customFontFile image masking config option. Multiple custom fonts and font files may be specified in a single context.
That was a snippet of setting up variables for file search and mask contexts in Python to send to the DarkShield API. The following image displays Python glue code to synthesize multiple check images in bulk from existing images.
Ten copies of each type of check are generated with different synthetic (test) values in each, and the glue code could be easily modified to generate many more copies. The image below just shows a subset of the 20 test checks generated in the code above:

The files are output to the local file system, but glue code offers the flexibility to output to any type of destination. The same file contexts are used for both types of check images since the relative locations of the data in the image are similar.

This example provides a template of how to generate test images in bulk, and can be modified for specific images and scenarios.
If you have any questions or comments about generating or producing safe test data for unstructured data sources, contact darkshield@iri.com. IRI also offers the RowGen product for generating structured test data in flat and EDI files, Excel sheets, ASN.1-compatible CDRs, and structurally and referentially correct RDB schema. Contact rowgen@iri.com with any questions about generating or managing test data.










