Synthesize Realistic DB Test Data with Set Files
Abstract: This article demonstrates how to synthesize realistic data to populate a full database schema with referential integrity in one operation via the IRI RowGen New Set File and New Database Test Data Job wizards in the IRI Workbench GUI for RowGen, built on Eclipse
RowGen builds rows of data in flat files, database tables, and reports, through either random generation of column values in specified data types, ranges, and distributions, or random selection of data from lookup tables or external “set files.” The choice of either method can be specified ad hoc, or as cross-table rules, on a column-by-column basis. As the title of this article implies however, we are covering just the latter method herein.
Set files provide greater realism for synthesized columns that contain names, places, addresses, and other proper nouns or non-numeric values. IRI ships several canned set files with the product, but they are otherwise very easy to obtain or create. See this article for more details.
Set File Creation
Set files are text files composed of one or more tab-separated columns of values or ranges. In the latter case, the set file would just contain a specially formatted range of values like dates between 01-01-1976 and 12-31-2001.
Set files work to facilitate test data generation by serving as the source of lookup values from which data is randomly selected and inserted into target fields. Set files must contain ASCII or EBCDIC readable characters and by convention, are given the filename extension “.set”.
There are many ways in which set files can be created including with a text editor, extracting fields from data files, through the IRI RowGen New Set File wizard on the IRI Workbench, and more. In this demonstration, I will show you how to create set files using the RowGen New Set File wizard. These set files will be used later to populate our database.
Follow along with our YouTube video!
Creating Set Files Using Wizards
From the top toolbar menu, select the New Set File wizard from the RowGen dropdown menu, shown in the screenshot below outlined in red.

Once selected, the “New Set File Wizard Selection” window will appear. In this window, the user is prompted to “Select a new set file wizard” from the list of wizards that create different types of set files. These include:
-
- Bucketing Values – Create a set file from creating discrete items by grouping the values of these items into categories that are defined by named ranges or named groups called buckets.
- Compound Data Values – Create a set file by combining generated components and literal values. Here data values are created to have a specific structure and are generated in pieces.
- Date Range Generator – Create a set file consisting of a random date, time, or timestamp range.
- Email Generator – Create a set file of random email addresses.
- Pseudo Set – Create a pseudo set file by using values from database tables or flat files in both columns.
- Pseudo Set from Column – Create a pseudo set file by extracting values from database tables and scrambling data.
- Range or Literal Values – Create a set file from individual literal entries or from ranges that are added to the set file.
- Set from Column – Create a set file by extracting values from a database table.
Select the wizard based on the type of set file needed then click the “Next >” button. Then follow the screens after in order to create your desired set files. This article covers set files and how to use these wizards in detail.
New Database Test Data Job
Now that we have our set files created for our database, we can use the New Database Test Data Job wizard in the RowGen menu to import them into our database. The screenshots below show how this process is done.

Once the New Database Test Data Job wizard is launched, the first screen displayed is the Define Destination screen. The screen allows you to specify the location, name, and options for the job.
In this example, I specified the folder name Retail and named the job new_batch, as seen below. After this screen is filled in with the correct information for the job click the “Next” button at the bottom of the Define Destination screen.

After the “Next” button is selected on the Define Destination screen the Database Object Selection screen will appear. In this screen, the connection profile and the tables that are to be used in the job are selected.
After all the tables needed for the job are selected, click “Next” at the bottom of the Database Object Selection widow. In this example, I selected 6 tables within the SQL Server Connection Profile, as seen below.

The next screen in the wizard is the Options window, where the parameters for generating test data will be entered. In the “Default Rows to Generate” box, enter the number of rows that each table will have if the “use default” column is marked as true.
If the number of rows for a certain table needs to be different from the default shown, uncheck the “use default” column and specify the desired number of rows in the “Rows to generate column”.
Next, select the Loader to use for the job in the “Loader” drop-down box. Then check “Truncate tables before insert” and “Temporarily disable foreign keys of tables before insert” at the bottom of the window. Click Next > to move on:

The next window to appear in this wizard covers Field Modification Rules. This is where matchers for field generation rules can be added or removed.
You can Browse … to select a previously created rule or Create … a new rule for each field. If you do not want to apply a common rule to like columns in your targets, you can just leave those out, as shown here:

Click Create … in the “Field Modification Rules” window to display the “Rule Matcher” window where you can name and associate a matcher for a generation rule with a specific column (or pattern for the column name) in your target table(s).
In this case, we want all tables with the string ADDRESS_ID in the column name to be populated with randomly selected values from a set file containing street addresses:

Specify the rule name in the Rule Name: box and provide the Details for the rule by either selecting one already created via Browse … or Create … a new rule via the New Field Rule Wizard Selection dialog.

The Set File selection window example below shows a typical file specification:

Click “Finish” to exit this wizard and insert the rule details into the Rule Matcher window.
To add the appropriate matcher to the column, click Add in the Rule Matchers window. This will open the Rule Matcher Details dialog where you can add the rule matcher details and then click “OK”.

Once all the appropriate rules have been added to the “Field Modification Rules” window click Next >. A summary window like this will display all the rules that will be applied to the target DB:

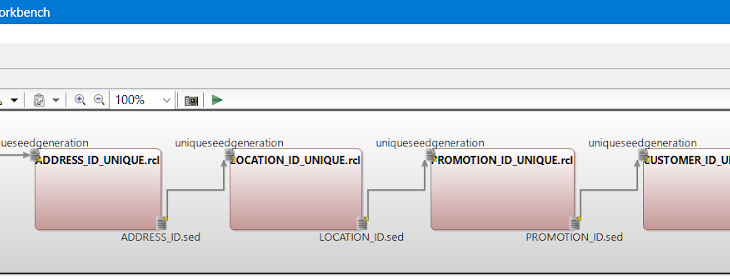
If everything in the summary looks good, click “Finish” at the bottom of the window to build the test data generation job. A multi-table task workflow dialog representing all the RowGen job scripts built is created:

You can also double click on any of these task blocks to see a table-specific “transform mapping diagram” reflecting the flow of columns from the generation to the output phase. The underlying job scripts will appear in the new_batch folder in the project explorer.
You are now ready to run the batch job by executing the .bat or .sh file that was built in that folder, either from Workbench or the command line, or from any CI/CD pipeline, job scheduler, or third-party test data provisioning application.
To run your job, right-click on the batch file and click Run As a Batch Program as shown here:

This actually runs the entire multi-table generation process where all the set file and otherwise generated data is automatically inserted into the corresponding tables and columns. By having the rule applied to like columns, referential integrity can also be preserved.
An example of one of the target test tables is shown here:

If you have any questions about this process or would like more information, please email rowgen@iri.com or leave a comment below.
Frequently Asked Questions (FAQs)