Table Lookups in SortCL-Compatible IRI Jobs
Introduction
SortCL, the IRI language of structured data definition and manipulation, has long had the ability to draw replacement values from external set files containing two or more columns of values. This capability is used for lookup transforms in CoSort-powered Voracity ETL operations, FieldShield pseudonymization and restoration functions, and random / valid-pair data selection in RowGen test data synthesis jobs.1
These set files are great for information that doesn’t change often. But because set files must be sorted by column contents, they can be cumbersome to use when rows need to be added — especially while the set file is open / in use.
In addition, the contents of a set file often actually originate in a database. In those cases, an extra step (like running the IRI Workbench ‘Set File from Column’ wizard, or a SQL operation) had to be added to the job flow to extract values from a table into a set file.
To address these drawbacks, the direct look-up of replacement values from existing database tables has been enabled. Lookups from a database table use the same syntax and structure for table lookups already in place for set files. This maintains functional consistency in SortCL jobs and provides access to more values (in multiple databases and set files) at once.
Syntax
SortCL field attribute syntax for accessing data in a set file has traditionally been:
SET="<Set_Source>"[<[ Search List ]>] [DEFAULT="string"] [ORDER=<Order Option>] [SELECT=<Select Option>] [SEARCH=<Search Option>]
where the <Set Source> parameter signifies the path name of the set file. This parameter can also now be an ODBC table name and connection string, just like the one used in infile or outfile statements. The Search List parameter should reference a single field from one of the input sources in the case of table lookups.
Your SortCL (or compatible) program will then look for a match between the value of this field and the lookup column in the database. If there is a match, then the value of the replacement column at this row will be used as the final value for the new field, which should have a different name than the field referenced from one of the input sources.
The table columns used in the lookup are specified in a single additional language element to the initial implementation of the SET sub-attribute: LOOKUP=”<lvalue>,<rvalue>”.
The parameter lvalue is the name of the column in the table that holds the value to be looked up. This corresponds to the left-hand, or first, column in a set file. The rvalue part corresponds to the right-hand column in a two column set file, and is whichever column holds the value to be returned as the replacement.
As with traditional set file lookups, a default value should be specified if there is no match. The DEFAULT=”string” syntax, where “string” is the manually specified default value, is used. There should be no commas between any of the set file parameters.
Putting it all together, a possible example of the syntax for a table lookup might be:
SET=”new_schema.info;DSN=New MySQL;” [ACCOUNT_NUMBER] LOOKUP=”ACCOUNTNUM,PHONENUM”
This should be a parameter within a SortCL field definition. The “info” table should have columns named ACCOUNTNUM and PHONENUM in this case.
How might these new set lookups be used in production? Consider these IRI job script examples:
Examples
Example 1: Pseudonymize data using replacement values from a database.
This FieldShield job looks up values from the “id” column in the table named “lookuptable” accessed through the DSN “Mangled”. If the ID field is the same in the input (a text file) as in the ID column of the referenced database table, then all fields in the output (also a text file) will be replaced with fake but realistic replacement values also from the same referenced table. If there is no match, the default values specified in the script will be output instead.
/INFILE=sensitiveData.txt /PROCESS=DELIMITED /INCOLLECT=200 # limit to 200 records /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="|") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="|") /FIELD=(SSN, TYPE=ASCII, POSITION=3, SEPARATOR="|") /FIELD=(ADDRESS, TYPE=ASCII, POSITION=4, SEPARATOR="|") /REPORT /OUTFILE=pseudonymizedData.txt /PROCESS=RECORD /FIELD=(PSEUDO_ID, TYPE=ASCII, POSITION=1, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”0123456789” LOOKUP="id,fakeid") /FIELD=(PSEUDO_NAME, TYPE=ASCII, POSITION=2, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”John” LOOKUP="id,fakename") /FIELD=(PSEUDO_SSN, TYPE=ASCII, POSITION=3, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”555-55-5555” LOOKUP="id,fakessn") /FIELD=(PSEUDO_ADDRESS, TYPE=ASCII, POSITION=4, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”583 West Ridge Rd” LOOKUP="id,fakeaddress")
Example 2: Pseudonymize three columns from a database table using replacement values from a different database, and encrypt the remaining column.
This script does a lookup based on the ID field taken from the database table named “inputTable”, looking at the “id” column from the table named “lookuptable” accessed through the DSN “Mangled”. The matching values in the “fakeid”, “fakename”, “fakessn”, and “fakeaddress” columns will be taken if there is a match from the input data ID field to the “id” column in the table. If there is no match, default values will be output instead.
The output will be sent to a separate target table. The output could also be sent to the same table as the input, which would mask the data in place.
/INFILE=”inputTable;DSN=Mangled;” /PROCESS=ODBC /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="|") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="|") /FIELD=(SSN, TYPE=ASCII, POSITION=3, SEPARATOR="|") /FIELD=(ADDRESS, TYPE=ASCII, POSITION=4, SEPARATOR="|") /REPORT /OUTFILE=”outputTable;DSN=Mangled;” /PROCESS=ODBC /FIELD=(PSEUDO_ID, TYPE=ASCII, POSITION=1, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”0123456789” LOOKUP="id,fakeid") /FIELD=(PSEUDO_NAME, TYPE=ASCII, POSITION=2, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”John” LOOKUP="id,fakename") /FIELD=(ENCRYPT_SSN=enc_fp_aes256_alphanum(SSN,”EPWD:p4PagGZq9k7JFaj6/J1/JQ==”, TYPE=ASCII, POSITION=3, SEPARATOR="|") /FIELD=(PSEUDO_ADDRESS, TYPE=ASCII, POSITION=4, SEPARATOR="|", SET="lookuptable;DSN=Mangled;" [ID] DEFAULT=”583 West Ridge Rd” LOOKUP="id,fakeaddress")
Example 3: Protecting Personally Identifiable Information (PII) using realistic replacements from a diverse set of masking methods.
The input file contains PII in several columns (fields). If there is a match between the first name field in the input CSV file and the “FIRST_NAME” column in the “NAMES” table, then a replacement last name will be output from the “LAST_NAME” column in that same table. The last names differ in the “NAMES” table from the personal data itself.
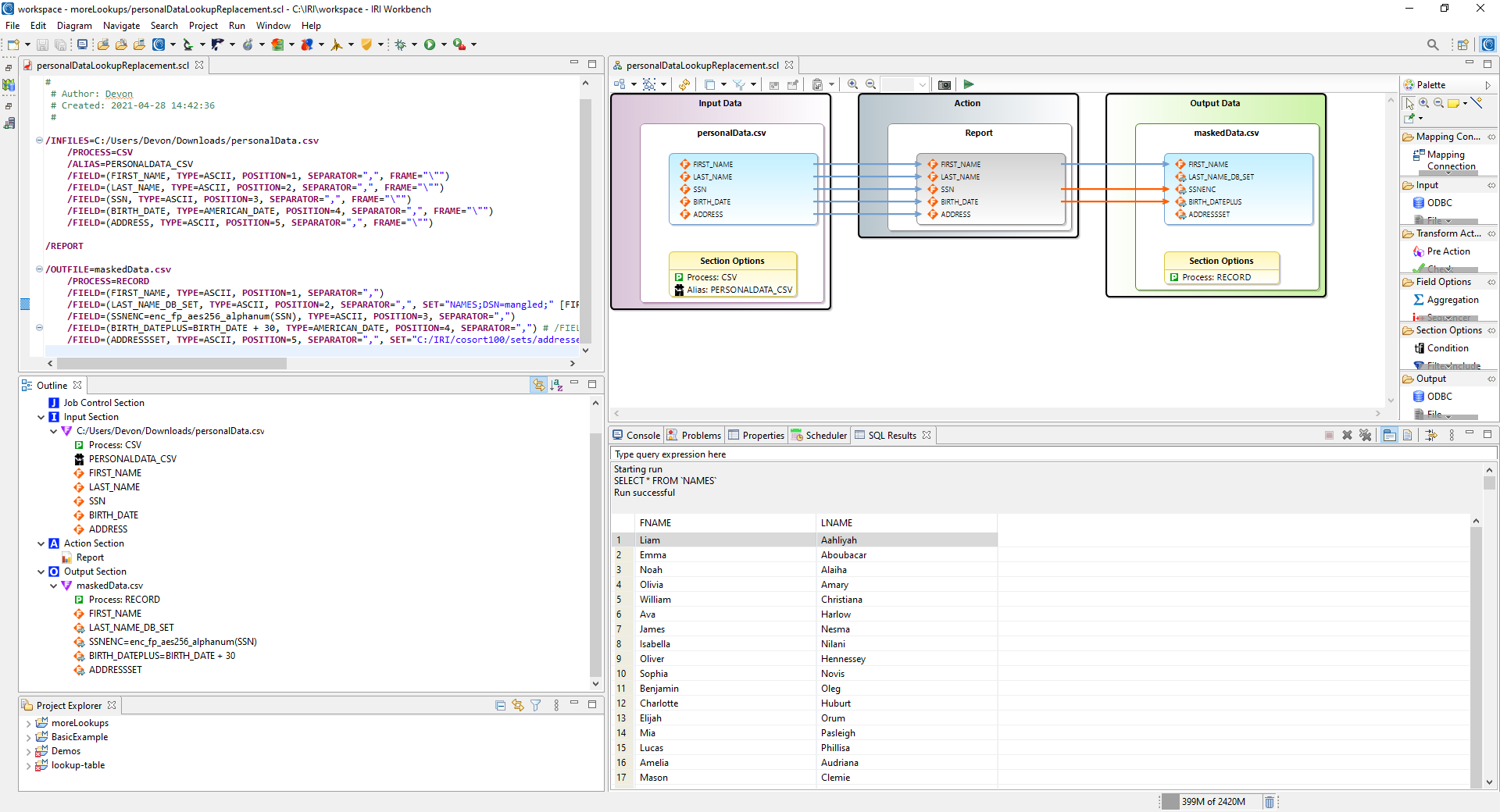
/INFILES=personalData.csv /PROCESS=CSV /ALIAS=PERSONALDATA_CSV /FIELD=(FIRST_NAME, TYPE=ASCII, POSITION=1, SEPARATOR=",", FRAME="\"") /FIELD=(LAST_NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",", FRAME="\"") /FIELD=(SSN, TYPE=ASCII, POSITION=3, SEPARATOR=",", FRAME="\"") /FIELD=(BIRTH_DATE, TYPE=AMERICAN_DATE, POSITION=4, SEPARATOR=",", FRAME="\"") /FIELD=(ADDRESS, TYPE=ASCII, POSITION=5, SEPARATOR=",", FRAME="\"") /REPORT /OUTFILE=maskedData.csv /PROCESS=RECORD /FIELD=(FIRST_NAME, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(LAST_NAME_DB_SET, TYPE=ASCII, POSITION=2, SEPARATOR=",", SET="NAMES;DSN=mangled;" [FIRST_NAME] LOOKUP="FNAME,LNAME") /FIELD=(SSNENC=enc_fp_aes256_alphanum(SSN), TYPE=ASCII, POSITION=3, SEPARATOR=",") /FIELD=(BIRTH_DATEPLUS=BIRTH_DATE + 30, TYPE=AMERICAN_DATE, POSITION=4, SEPARATOR=",") /FIELD=(ADDRESSSET, TYPE=ASCII, POSITION=5, SEPARATOR=",", SET="C:/IRI/cosort100/sets/addresses.set" SELECT=ANY)
The same job script, outline an mapping diagram, along with the original name table is shown in my IRI Workbench IDE, built on Eclipse, below:
Example 4: Generating referentially correct test data with IRI RowGen
Consider a database table, or in other potential cases multiple tables, that hold data that correspond to a certain date. With IRI RowGen and table lookup functionality, it is possible to take a selection of dates (from a set file or randomly generated) and add on more fields in the output that correspond to realistic values based on the date input provided.
In this example, all of the corresponding data from the date is held in the lookup table shown below (though it could be taken from any number of tables). The table has a year’s worth of dates and the corresponding related values:

From the set file in the DATE input field, 3 dates are selected that are within the range of dates included in the table.
The set file includes three entries: 2019-10-11, 2019-11-11, and 2019-12-11.
/INFILE=random_file_placeholder /PROCESS=RANDOM /INCOLLECT=3 /FIELD=(DATE, TYPE=ALPHA_DIGIT, POSITION=1, SEPARATOR=",", SET="C:/Users/Devon/Downloads/dates.set" SELECT=ALL) /REPORT /OUTFILE=testPriceData.xml /PROCESS=XML /FIELD=(DATE, TYPE=ALPHA_DIGIT, POSITION=1, SEPARATOR=",") /FIELD=(OPEN, TYPE=ALPHA_DIGIT, POSITION=2, SEPARATOR=",", SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="170" LOOKUP="Date,Open") /FIELD=(HIGH, TYPE=ALPHA_DIGIT, POSITION=3, SEPARATOR=",", SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="171" LOOKUP="Date,High") /FIELD=(LOW, TYPE=ALPHA_DIGIT, POSITION=4, SEPARATOR=",",SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="169" LOOKUP="Date,Low") /FIELD=(CLOSE, TYPE=ALPHA_DIGIT, POSITION=5, SEPARATOR=",",SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="170.5" LOOKUP="Date,Close") /FIELD=(ADJ_CLOSE, TYPE=ALPHA_DIGIT, POSITION=6, SEPARATOR=",",SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="170.5" LOOKUP="Date,Adj_Close") /FIELD=(VOLUME, TYPE=ALPHA_DIGIT, POSITION=7, SEPARATOR=",",SET="new_schema2.pricedata;DSN=New MySQL;" [DATE] DEFAULT="523210182" LOOKUP="Date,Volume")
The output from this example is a standard XML file containing the lookup values:

Example 5: Performing a Lookup Transform in an IRI Voracity ETL and Reporting Job
In this example, we have a CSV file containing account numbers and past due amounts for several customers. A table lookup will be used in two fields in the output to get additional matching information from a master customer fact table in MySQL, with that table serving as the master customer table.
The master table does not have information about the amount due and contains many more customers than the input file which only shows delinquent customer accounts. This looks up the name and phone number from the table based on the account number and outputs to an .XLSX spreadsheet in a handy report format with customer contact information.
 Input CSV
Input CSV
 Snippet of the Master Customer Table to be looked up against
Snippet of the Master Customer Table to be looked up against
/INFILE=C:/Users/Devon/Downloads/accountnumsandamountDue.csv /PROCESS=CSV /ALIAS=accountnumsandamountDue /FIELD=(ACCOUNT_NUMBER, TYPE=ASCII, POSITION=1, SEPARATOR=",", FRAME="\"") /FIELD=(AMOUNT_DUE, TYPE=ASCII, POSITION=2, SEPARATOR=",", FRAME="\"") /REPORT /OUTFILE="'Past Due',HEADER;report.xlsx" /PROCESS=XLSX /FIELD=(ACCOUNT_NUMBER, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(LOOKUP_NAME,TYPE=ASCII,POSITION=2, SEPARATOR="\t",SET="new_schema2.info;DSN=New MySQL;" [ACCOUNT_NUMBER] LOOKUP="ACCOUNTNUM,NAME") /FIELD=(LOOKUP_PHONE,TYPE=ASCII,POSITION=3, SEPARATOR="\t",SET="new_schema2.info;DSN=New MySQL;" [ACCOUNT_NUMBER] LOOKUP="ACCOUNTNUM,PHONENUM") /FIELD=(AMOUNT_DUE, TYPE=ASCII, POSITION=4, SEPARATOR="\t")
 Output “Past Due” report
Output “Past Due” report
IRI Workbench Support
Database table lookups may be set up as a rule from the New Field Rule Wizard. This type of rule is referred to as a “Table Lookup” under Generation Rules, but it can be used in multiple sources or targets as a field rule in other jobs.

When selecting a table lookup as a rule, a connection profile must be either already set up or created when prompted in order to access the database tables and column names to choose from.

From there, select the table, lookup column, and replacement value column to use for the lookup. Now this table lookup may be set as a rule to be applied based on matchers.
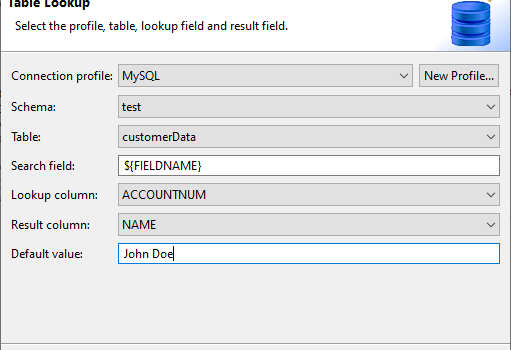
Sets may be modified from the Set:Table Lookup value transformation type within the field editor dialog.

This is not needed if a table lookup field rule has already been set up and applied. However, this dialog allows for manual editing of table lookup components such as DSN, table, search field, lookup column, and result column. A default value may also be specified here.
Summary
Set lookups now have a new possible source in SortCL that can greatly expand and ease obtaining the data needed for a lookup. This is useful in masking or data generation operations to provide realistic replacement values that preserve relationships.
In the future, sets may be expanded to include even more data sources. Contact your IRI representative for more information.
- Note that presently, RowGen users leverage set files for the random selection of values without a lookup parameter. This functionality is not supported in the first implementation of DB table lookups. This is because each database has a specific method or syntax for selecting a random row from a table; some databases may not support random selection at all.










