Selected Questions and Answers
Important note: The FAQs below are not a comprehensive resource, and only address a fraction of the available capabilities in IRI software or questions people ask.
Please visit the IRI solutions and products sections to learn more. Also, do not hesitate to contact us if you have any questions, or need details on specific features or options applicable to your use case(s).
+ BI & Analytics
What kinds of analytics can Voracity perform?
IRI Voracity provides analytic capabilities in five ways, with two more pending in 2019:
1) Embedded reporting and analysis - via CoSort SortCL programs that write custom detail, summary, and trend reports in 2D formats complete with cross-calculation, and other incorporated data transformation, remapping, masking and formatting features. The reports can be descriptive, or through more fuzzy logic and functions like standard deviation -- and Boost-driven statistical and BIRT-driven linear regression graphs -- predictive.
2) Integration with BIRT in Eclipse - where at reporting time, BIRT charts and graphs you design get populated with 'IRI Data Sources' via ODA support for Voracity/CoSort SortCL output. What's interesting about this in-memory transfer of SortCL data and metadata to BIRT that the data integration/preparation get run when the report is requested, saving time as well as resources by having data prepared outside the BI layer (with CoSort or Hadoop engines)
3) Data preparation (franchising) that accelerates time-to-visualization for 10 third-party BI and analytic vendor platforms. This section of the IRI blog site features benchmarks run when SortCL (available to Voracity or CoSort users) alone runs ahead of BOBJ, Cognos, Microstrategy, QlikView, Splunk, Spotfire, R, and Tableau.
4) There is also a direct Voracity add-on for Splunk to feed data to Splunk for analysis there.
5) Integration with a cloud dashboard from DWDigest for interactive business intelligence you can customize and view in any browser, including the internal web browser in the IRI Workbench GUI for Voracity, built on Eclipse.
6) Streaming anlalytics (pending) through JupiterOne, where Voracity can be a source of Kafka-fed data streams, or a target for further procressing of live sentiment analysis data.
7) Colocation and integration with the KNIME Analytic Platform in the IRI Workbench IDE for Voracity, built on Eclipse, to allow citizen data scients to punch above their weight with machine learning, artificial intelligence, neural networks, unstructured data, and other advanced data mining nodes and projects.
It can be. CoSort offers a range of solutions for generating meaningful reports from huge volumes of data. You can use CoSort's SortCL (4GL) program as a standalone report generator, or as a staging tool to digest and hand-off large volumes of data.
Not only does SortCL transform and protect huge volumes of disparate data from a variety of RDBMS sources, and sequential or index files, plus web and various device logs (including ASN.1 TAP3 CDRs). It can also join, aggregate, calculate, and display that data in custom detail and summary report formats, complete with special variables and tags for web pages.
By creating output in .CSV and .XML formats, CoSort's SortCL tool can directly populate spreadsheets like Excel, databases, ETL tools, and BI tools. See the next question in this section, or:
Which third-party BI/analytic platforms does CoSort (or Voracity) optimize?
Any and all tools that can import CSV and flat XML files, or RDBMS tables ...
IRI software's job in these cases is to prepare or "wrangle" big, structured data in a centralized place. CoSort or Voracity users create Sort Control Language (SortCL) programs in 4GL text scripts -- or through wizards in the free IRI Workbench GUI, built on Eclipse™ -- that transform (filter, sort, join, aggregate, mask/encrypt, pivot, pre-calc, etc.) data in more than 125 sources prior to the hand-off.
SortCL programs or Voracity targets can directly populate spreadsheets like Excel, databases (relational and NoSQL), ETL tools, and BI tools, including:
- SAP Business Objects
- IBM Cognos
- DI-Diver from Dimensional Insight
- DWDigiest from NextCoder
- iDashboards from iViz
- Microstrategy
- Oracle DV / OBIEE
as well as newer analytic platforms, such as:
- Knime
- Power BI
- QlikView
- R
- Splunk
- Spotfire
- Tableau
In addition, ODA driver support in the IRI Workbench provides seamless data and metadata flows between CoSort/SortCL data preparation and BIRT presentation. There is also a Splunk Add-on for Voracity, plus support for the DWDigest cloud dashboard app from NextCoder, and upcoming Voracity feeds through Kafka to streaming analytic platforms like JupiterOne and integration with the KNIME Analytic Platform in the same pane of glass.
For more information, please see:
+ CoSort & Compatible IRI Product Installation
How do I install and license the product(s)?
Installation of IRI Voracity and its component (or standalone) products -- IRI CoSort, NextForm, RowGen, FieldShield and DarkShield -- require a back-end CoSort package installation and licensing of the SortCL program executable that runs all those jobs on Windows, Linux, mac OS, AIX, Solaris or HP-UX systems.
The IRI Workbench graphical front-end, built on Eclipse, is an optional install for Windows, Linux and MacOS. Workbench is also packaged with the Windows version of CoSort. Workbench also supports IRI Fast Extract (FACT); FACT requires a separate install and license.
Installation steps for all of the above, including the COBOL edition of NextForm, are documented in this guide.
Separate installation instructions for Voracity, CoSort, FieldShield, DarkShield, and RowGen APIs, as well as the proxy-based DDM option for FieldShield, are available on request.
What is the difference between a fixed and floating license?
What version of RHEL are compatible with which versions of CoSort?
For older unsupported versions of CoSort like 9.x, IRI relies on the compatibility libraries supplied by Red Hat with newer versions of RHEL. More details are in this article addressed for those with a development backtround:
No, you only need a database login with sufficient rights to read or write data and metadata to support whatever operation is desired. To read data from a table, and write it to a file, only read permissions on the database would be indicated. To be able to create a new table, and insert data into it, more permissions would be needed. To read data and then modify the rows in place using UPDATE, yet a different set of permissions might be required.
IRI Workbench is the Eclipse front-end (graphical job design client) piece, which runs on Windows, Linux, and macOS. The back-end SortCL program in the CoSort package/Voracity platform -- which is the data manipulation, mapping, munging, masking, and mining engine -- runs on all the above, plus all flavors of Unix including AIX, Solaris, HP-UX, and z/i/pSeries Linux. Native hosts or virtual machines should be considered similarly for this discussion.
Again, because SortCL is the back-end engine, and IRI Workbench is the front-end, for multiple IRI products, this answer applies not only to CoSort (sort) and Voracity (ETL, etc.) jobs, but also to FieldShield, RowGen, NextForm, and DarkShield. The requirements for Windows and Linux are similar as far as hardware is concerned.
The absolute minimum requirement for CoSort/SortCL CLI operations (only) is 40MB of RAM, but at least 512MB-2GB is recommended as a minimum for system RAM available to the CoSort user. Sort jobs that can fit entirely in memory are generally faster, and it's not uncommon for modern CoSort hostnames to be configured with 64GB-2TB of RAM to sort without the I/O overhead of work files.
The minimum configuration for Workbench is 4GB of RAM and 10GB of free disk space, after the installation of any VMs, DBs, etc. Workbench includes a JRE. Workbench and CoSort are tested and supported back to XP on Windows. We also test with various major Linux distributions of both Debian and Red Hat package management standards. However, 6GB and up works best for each system to accommodate multiple database connections and table parsing for metadata and job definition. In fact, for schema with hundreds of tables to enumerate, as much as 64GB of RAM could be appropriate for the Workbench machine(s) where DB-related jobs are built.
We recommend where possible co-location of the licensed back-end (SortCL executable) on, or within close network proximity to, your database source or target server(s) for performance reasons, particularly if there are known network bottlenecks. When it comes to data masking in FieldShield, DarkShield, and test data generation via RowGen, the bottleneck is typically in network performance AND I/O; the time it takes you currently to read and write your data now is roughly the time it will take you to mask, subset, or synthesize it, too. This is therefore another reason for same-system colocation where possible, or at least optimal I/O subsystems for the software use in volume (e.g., fibre channel, SSD, multi-core, fewer conncurrent processes, etc.).
If you are going to also run that CoSort engine on the same PC as Workbench, then you will have to allow extra capacity to run jobs. The requirements for the program increase with the size of the data that you intend to process at any one time. A recommended hardware platform for a PC running Workbench would be 8GB of RAM, and 10GB available disk space, plus additional disk space for temporary files equal to 1.5 times the largest data set to be processed. A general guiding principal for hardware is that the more RAM, the better the performance.
For more information on CoSort-specific tuning recommendations, see this article:
https://www.iri.com/blog/iri/business/frequently-asked-cosort-tuning-questions/
Many 'big data' CoSort and Voracity users license and cosortrc-tune the product on very large multi-core Unix systems to leverage hundreds of GB of RAM to out-perform Hadoop for example. If you run the Hadoop edition of Voracity, load balancing should be automatic. For DarkShield masking jobs through the API, multi-node load balancing is also possible through the NGINX reverse proxy server.
For an EC2 Linux instance running the job scripts only, a t2.small or t2.medium should work. For a Windows instance running both job design and runtime, a t2.large or even t2.extra-large would be better. Also t3 instances of the same configuration are sometimes cheaper, but often require more expensive storage.
Yes. This is no different than installing CoSort on a Unix server for multiple users. Note also that installing Cygwin and allowing users ssh access would work well too. The problem with this approach is the access to the input/output data streams — which would need to be network resources — possibly slowing runtimes considerably.
Can IRI software run in a container (like Docker)?
The command line tools within the Voracity platform / CoSort package, like sortcl-compatible and *2ddf programs -- as well as the DarkShield web service -- will run fine in Docker or other containers. The configuration requirements are the same as for traditional use. The container will need to have a consistent hostname, in order for traditional IRI licensing to work, but if not, other arrangements can be made.
The same required files, especially a fixed or floating license file, must be present in $COSORT_HOME/etc, and the environment variable exported. Since there is no network interface available to execute jobs, some mechanism must be configured to trigger the command line invocation of the desired utility. It is also possible to run a secure shell daemon (sshd) in the container to interface to the command line through a network port with ssh.
IRI Workbench will, and certain application calling (glue code) programs may, need to run outside the container.
How do I install IRI Workbench for Linux or macOS?
.eclipseproductartifacts.xmlconfiguration/features/icon.xpmiri-workbenchiri-workbench.inilicense.txtp2/plugins/readme/validators/
$HOME/iri/workbench2/
+ CoSort Installation Issues
How do I set up the correct COSORT_HOME environment on Windows?
The CoSort package, containing the sortcl executable, must be installed on the system shown to run the shown batch script. The batch script does not include the full path to the sortcl executable, therefore the path to the sortcl executable must be included in the PATH environment variable.
For example, in CoSort 10.5 on Windows, ensure that the folder C:\IRI\cosort105 exists on the system, the environment variable COSORT_HOME is set to it, and the environment variable PATH includes the value %COSORT_HOME%\bin.
I am getting an invalid key (error) message from CoSort on Windows. What can I do to fix this?
In Windows 10 or 11, make sure you have edit (not just write) permission for the C:\IRI\CoSort105\etc\cosort.lic file. Without that, the setup program cannot update its 3-string license key value with what the keys you tried to input through the command line or IRI Workbench setup and registration program (Update License option). You may even have to insert those instead by hand, replacing the default 0.0.0 values.
For Windows 2003, first, double check that the license keys you entered were provided for the current (and correct) private key in your RegForm.txt file. If so, the registry was not properly updated. To rectify this, open the main directory where you installed CoSort (C:Program FilesIRICoSort82) and double click on global_config.reg and license.reg to re-set these Windows registry settings. To verify that they have been set-up correctly in the registry, click Start, Run, and enter the command REGEDIT. Click OK and to open the registry and navigate to:
HKEY_LOCAL_MACHINES->Software->Innovative Routines Intl -> CoSORT82
Check for these 2 folders: Global Configuration and License. If the folders are there, please run the C:Progra~1IRICoSORT82/setup program again re-enter your license keys.
(When) can I use the same Serial Number?
I have CoSort Unix. After installation, I am getting a file error.
Check the LOG file entry in $COSORT_HOME/etc/cosortrc. If you use v8.2.1, make sure that it does not have a %s in the path. You (and all CoSort users) must have read and write permissions for the path/LOG file (default location should be $COSORT_HOME/etc/cosort.log) and the sort overflow (WORK_AREA) directories.
+ CoSort Sorting Apps & Performance Tuning
CoSort is a robust, commercial-grade software package for efficiently manipulating and managing high volumes of data. More specifically, it is a sorting, data transformation, migration and reporting package that addresses a very wide range of enterprise and development-related challenges in data integration, data masking, business intelligence, and ancillary disciplines. Please review the product description and solution sections of this web site for details.
For the purpose of this simple sort/merge question, CoSort stands for Co-routine Sort, first released for commercial use
| On | In |
| CP/M | 1978 |
| DOS | 1980 |
| Unix | 1985 |
| Linux | 1990 |
| Windows | 1995 |
| IBM i/Z | 2000 |
CoSort exploits parallel processing, advanced memory management and I/O techniques, as well as task consolidation and superior algorithms, to optimize data movement and manipulation performance in existing file systems. No paradigm shifts to database engines, NoSQL, Hadoop, or appliances are necessary. Maybe a little more RAM, but that's usually enough ...
Very. Performance varies by source sizes and formats, data and job orientation, hardware configuration and resource allocation, concurrent activity and application tuning. The best benchmarks (e.g. 1GB in 12 seconds, 50GB in 2 minutes) run in memory on fast, multiple CPU Unix servers.
When you perceive a bottleneck, which could be starting at 500K to 50M rows depending on your hardware. CoSort sorts routinely in the terabyte range -- and scales linearly in volume without Hadoop. Input files in the dozens or hundreds of gigabytes are now common. Any number of input and output files -- and structured file formats -- are simultaneously supported, including line, record and variable sequential, blocked, CSV, I-SAM, LDIF, XML (flat), and Vision. For a list of supported data sources, click here.
CoSort is now also the default engine in the IRI Voracity ETL, BI/analytic data preparation, and data management platform which can also run many CoSort data transformation and masking jobs (scripted in SortCL 4GL syntax and/or represented graphically in the IRI Workbench GUI) seamlessly in Hadoop. Thus the question may be at what volume point would I need to run such jobs via a Hadoop engine instead. See our article, When to Use Hadoop.
How would I tune CoSort? What would I tune?
Usually through a CoSort Resource Control (cosortrc) text file, which can be global, user, and/or job-specific. On Windows, default registry settings also set up at installation time and can be overridden by an rc file. You can specify a ceiling and floor on CPU/core threads and memory, I/O buffers, and allocate/compress disk space for sort overflow. There are several other documented job controls also specified at setup, and easily modified (or secured) later.
Typically the single most important factor in file sort performance is the speed of the I/O channels. For small files, which may be sorted entirely in memory, this means optimizing the reading of the source files, and the writing of the target files. For large files, which will exceed the available memory, The throughput to the work area files will also be critical. Many times, the source and target file locations are fixed, and little can be done to improve their I/O performance. However, the local work areas where the temporary merge files are stored can often be optimized. For example, having more than one fast SSD type local drives, on separate controllers, can make overflow sorts almost as fast as in-memory sort jobs.
The location of the overflow files is specified by the WORK_AREAS tuning settings. Multiple locations can be specified, but there is no advantage to using multiple locations unless they are on separate devices and I/O channels. At a minimum, there should be at least one fast local drive that is not shared with either the source or target files.
After addressing the performance of the I/O channels, the next most important tuning settings are the ones related to memory usage. Fortunately, CoSort 10 has some new and powerful techniques to self-tume the memory allocation. We recommend starting with the CoSort 10 default settings for memory settings. This is best accomplished by having only the single setting of:
MEMORY_MAX AUTO
in the $COSORT_HOME/etc/cosort.rc file. Other memory related settings, like BLOCKSIZE and COMPRESS_WORKFILES will then be controlled by the intelligent algorithms in CoSort 10. Here is an example tuning file using the recommended settings. Of course you will want to set THREAD_MAX to a value up to the number of CPU cores that your license allows. In this example, the two work areas would be on local solid-state drives on two separate dedicated controllers.
THREAD_MAX 6 # Maximum number of sort threads
THREAD_MIN 1 # Minimum number of sort threads
MEMORY_MAX AUTO # Internal sort memory ceiling
WORK_AREAS /mnt/ssd1/work # Overflow (temp) file paths
WORK_AREAS /mnt/ssd2/work # Overflow (temp) file paths
MONITOR_LEVEL 0 # Runtime monitor level
MINIMUM_YEAR 70 # Century window
ON_EMPTY_INPUT PROCESS_WITH_ZEROS # Output file option
OUTPUT_TERMINATOR INFILE # Output terminator
Please email to support@iri.com with any additional questions or concerns.
An external sort is defined as a sort operation which is too big to fit into memory, and must use temporary work files (LWF). In this case, there will be one physical work file created for each thread and work area combination. The amount of memory used while READING the input will be approximated by the formula:
THREAD_MAX * AIO_BUFFERS * BLOCKSIZE * number of WORKAREAS
However, during the merge phase, when WRITING data, much more memory is required, because each physical file can contain multiple logical work files (LWF). As the volume of data increases, the amount of merge memory required will increase. If there is not enough memory available from the MEMORY_MAX setting, and insufficient merge memory error (error 2) will be raised. The remedy is to increase MEMORY_MAX, or decrease any of the other settings involved in the memory usage calculation.
How do we determine the best number of cores to use / threads to license?
CoSort will begin using multiple threads when the sort (input file/table) volume is at least two times larger than the BLOCKSIZE specified in your CoSort Resource Control (cosortrc) file, which is typically 1 to 2 MB in an auto-tuned job.
CoSort does not make any distinction between physical CPU chips, CPU cores, or hyper-threading. We do not attempt to micromanage which device a thread is created on. The operating system is in the best position to determine where to schedule new threads. CoSort just creates the sort threads, up to the maximum number specified in the tuning file, which cannot exceed the number of threads supported by the license. Cores are usually the best indicator of what's possible to expect in terms of peak performance before the point of diminishing return, subject to resource contention and Amdahl's Law.
Note also that each CoSort sortcl process is independent of all others. There is no inter-process communication or synchronization taking place, so in a concurrent multi-job environment, specifying only 1 or 2 max threads will likely be more efficient, even when each job running simultaneously may be high volume. Memory, however, is self tuning when on MEMORY_MAX is set to AUTO.
For testing different numbers of threads, we recommend that you request a license key through the normal CoSort installation and registration process (as instructed in the installation guide) for a temporary period, wherein you specify the total number of physical cores on the host machine. Then once you get the license keys to allow that number (up to 64), run jobs with different THREAD_MAX values (from 1 to the max) in your cosortrc file. You can also experiment with memory and overflow-related settings to see what works best.
Please advise support@iri.com if you need more details, and consult Section D of the Appendix chapter of the CoSort manual for technical specifics, and a way to automate the benchmarking process. Remember that your runtime results are logged so you can analyze performance off line later.
Is there any way to bind a CoSort thread to a specific core?
There is no way to specify which CPU core threads will use. This is entirely up to the operating system. If your operating systems supports it, you can try using system tuning to assign sortcl processes to certain chips or cores.
CoSort has no inter-process communication; each instance stands alone. So if MEMORY_MAX is set to 10%, and you run two simultaneous jobs, you would be using 20% of the system memory.
Yes. A higher BLOCKSIZE will help read/write performance if the source and work file locations are on the same device, otherwise, a lower BLOCKSIZE is better. Test with various block sizes from 100K up to 16M. Just remember that on large, external sorts, insufficient merge memory may result from using too big of a BLOCKSIZE.
Can I increase AIO_BUFFERS beyond 2, and if so, what other parameter(s) should be adjusted?
The AIO_BUFFERS parameter is the number of buffers used for reading and writing. CoSort uses overlapped I/O, which means that while one buffer is being processed, another is being read or written. A slight increase in speed is possible by increasing the number of buffers, but will come at the expense of needing more merge memory. Use any value greater than the default with caution. Test first with the largest input size that will occur. Check to see if the performance gain is measurable.
What about monitoring and logging (statistics)?
CoSort users can display runtime information before, during, and after execution through:
• optional on-screen display levels
• self-appending and replacing log files
• application-specific statistical files
• and, a full audit trail for various compliance and forensic requirements
What data types does CoSort support?
More than 120 now, and counting. These includes single and multi-byte character sets, Unicode, C, COBOL, and mainframe numerics. Contact IRI to help obtain a definition if you are not sure what you have. Moreover, CoSort supports the (simultaneous) collation, conversion, and creation of more than two dozen file formats.
How do I suppress $SORTIN/OUT lines when converting MVS sort parms to CoSort SortCL scripts?
I am using the translation tool mvs2scl and I have mvs scripts that are similar to this:
OMIT COND=((63,1,CH,NE,C’ ‘))
INREC FIELDS=(1:1,20,21:40,3)
SORT FIELDS=(1,20,CH,A)
Your mvs2scl utility produces this output from the conversion:
/INFILES=($SORTIN)
/FIELD=(field_1, POSITION=1, SIZE=20)
/FIELD=(field_2, POSITION=40, SIZE=3)
/FIELD=(field_0, POSITION=63, SIZE=1, EBCDIC)
/CONDITION=(cond_0, TEST=(field_0 != ” “))
/OMIT=(CONDITION=cond_0)
/INREC
/FIELD=(field_1, POSITION=1, SIZE=20)
/FIELD=(field_2, POSITION=21, SIZE=3)
/KEY=(field_1, ASCENDING)
/OUTFILE=($SORTOUT)
This is fine, except that I do not want the lines that have $SORTIN or $SORTOUT.
Q. How can I suppress these lines?
A. There are no specific mvs2scl options that will do this. But there are options with the grep command that can be used while executing the translation. Here is what you should execute on the command line.
mvs2scl job1.mvs | grep -v ‘$SORT’ > job1.scl
job1.mvs is the mvs script that is to be translated. job1.scl is the translated script for sortcl without the $SORTIN or $SORTOUT lines. The -v option with grep says to only output lines that do not contain the expression $SORT.
How and where does your SAS sort replacement work?
SAS documents the CoSort option in the v7 and 8 system for Unix, which is reflected in the SAS and CoSort user manuals. The use of CoSort has been proven to dramatically and affordably accelerate native SAS PROC performance off the mainframe! In SAS, CoSort performance is tuned automatically, or through a resource control file that is configured at set up time by the system administrator. This text file can be modified at any time for reference at a global, user or job level.
For SAS 9 and later however, please contact SAS, as they yet updated their 'sort appendage' for CoSort. IRI has made repeated requests to, and offered to help, SAS update their CoSort connection and give their users a better option. But SAS told us that you must make your CoSort request known directly to them. When you do, please notify us through this form at the same time so that we can follow up with SAS for you, too. Thank you!
How do these plug-ins or conversion tools work?
They differ, and are based on collaboration and feedback with partners and customers who own their data and job definition metadata.
+ Data Security (PII Classify, Search, Mask) -- IRI *Shield Tools (Voracity / Data Protector Suite)
N.B. The information below summarizes the details of this comparison article you may wish to read instead/as well.
Either:
IRI FieldShield for structured data, connected via both ODBC and JDBC drivers per DB-specifc installation steps inked here
or
IRI DarkShield for structured data, plus what's in C/LOB columns, and connected only via JDBC.
can find and mask sensitive data in relational databases, and are priced the same for them. Your use case should determine which one is a better fit.
The principal differences between FieldShield and DarkShield are that:
- DarkShield can search and mask separately or simultaneously, while FieldShield performs them separately;
- DarkShield cannot as handily map masked results to different kinds of targets (except the same RDB or a flat file), while FieldShield can go to other structured DB, file, and report targets (even all at the same time, ETL-style);
- Only DarkShield can also handle semi- and unstructured data source masking in case of you EDI files, raw text, documents, images, NoSQL, Parquet, etc.;
- Conversely for purely structured sources, FieldShield masking jobs are metadata-compatible with subsetting, incremental masking, test data synthesis, cleansing, ETL, reporting/wrangling, etc. thanks to its use of the SortCL data definition and manipulation program; and,
- FieldShield is needed to support input phase filtering via SortCL include/omit or SQL query syntax -- as well as complex target field logic to address business needs, which may involve combined masking and string transformations, joins, conditional masking rules, reformatting, etc.
However, both DarkShield and FieldShield:
- run on premise by default, but can also run in the cloud, and support LAN, Sharepoint, and Azure, S3 and GCP buckets;
- use the same data classifications and masking functions to maintain structural and referential integrity in the target schema;
- share the same IRI Workbench graphical IDE, have callable APIs, can be integrated into DevOps pipelines, and can run in CLI jobs;
- are included components, along with IRI RowGen (for DB subsetting and synthesis) et al, in the IRI Voracity data management platform; and,
- are subject to similar considerations for licensing in DB environments, which are advised in this FAQ.
It is not uncommon to license both products in a discounted bundle or Voracity platform transaction to satisfy multiple use cases, including for database sources alone. Please email info@iri.com with details about your requirements and request an online meeting for a discussion and/or live demo so you can be fully informed.
This varies by use case, but insofar as RDB sources or targets are involved, DBA skills are preferred during deployment, along with knowledge of data structures and sources.
CDO/CISO or data governance/security stakeholders should also be involved in the definition (classification) of what types of data are sensitive and what masking functions (rules) should be applied to the data classes.
Data scientists would be helpful in ML/AI aspects related to DarkShield NER model deployment. BI/analytics architects familiar with existing visualization platforms are helpful for leveraging anonymized output data, PII search reports, and operational logs for insights and action.
Familiarity with Eclipse, Git, 4GL/3GL (for API use), as well as relevant cloud connections would be good know-how for production users, too.
TDM architects can also be valuable in defining / configuring, as well as provisioning masked, subsetted, or synthesized data.
Which IRI data masking (shield) product should I be looking at?
This depends on your data sources, targets, and to some extent the kind of functionality you require. See this selection matrix, and note that for DB subsetting and test data you would need IRI RowGen or the IRI Voracity platform which includes subsetting, RowGen synthesis, and all the *shield products.
How do I get ciphertext consistency (and thus referential integrity) with your masking tool?
By consistently applying the same deterministic data masking function to the same plaintext each time, automatically and globally. This is done through rules associated with pattern-matched column names, or more reliably, through integrated data classes tied to identified data. Classified data is discovered / validated through built-in value search methods like RegEx pattern matches with custom-set accuracy thresholds, lookup value matches, fuzzy-match algorithms, named entity and facial recognition models, or JSON/XML/CSV/DB path (column) filters. Note that all IRI shield products -- FieldShield, DarkShield, and CellShield EE -- share the same data classes and deterministic masking functions to facilitate consistency, and thus data and referential integrity post-masking across your enterprise structured, semi-structured, and unstructured sources.
Notably, IRI's integrated data classification functionality also precludes the need for formally defined primary and foreign keys in database schema construction. This supports data integrity in relational databases without constraints just as it does in files, documents, and images.
Where constraints must be defined to automatically support referential integrity in artifically generated RDB test data are in the IRI DB subsetting wizard and DB test data synthesis wizards. If those constraints are not defined, it is still possible to subset and synthesize test data for DBs, but more manual intervention is required.
Right, as there are more use cases and invocation methods than we can keep updated here. However there are a couple demo videos linked on our self-learning page in the unstructured sources section (scroll down). And, and we can demonstrate specific solutions via https://www.iri.com/products/live-demo. There are multiple AI models already in the product that use machine learning to discover sensitive data across structured, semi-strutured, and unstructured sources, and IRI is continuing to introduce more. Please ask us about them relative to your use case.
Yes, per an external command line interface (CLI) call described with examples in this document. DarkShield also has an RPC API that can be interacted with through web requests from a custom calling program.
Does the tool already have the masking rules predefined for the financial sector?
Privacy law groups and sensitivity classifications are provided out of the box, but the rest of the default masking rules are not sector specific. The default rules are likely to conform already however; e.g., FPE for PANs, pseudonyms for names, redaction for TINs. It is easy to modify both data classes and data class groups and their associated rules of course, per this article
https://www.iri.com/blog/data-protection/iri-data-classification/
and that is typically only something you would need to do once. There is a wide variety of options for masking rules, per:
https://www.iri.com/solutions/data-masking/static-data-masking
Which protection techniques can I use? What should I use?
Whichever satisfies your business requirements. In IRI FieldShield (or the SortCL program in IRI CoSort), you can apply any of these techniques on a per-field/column basis:
- Encryption
- Masking
- Hashing
- Pseudonymization
- Randomization
- De-ID
- Expression (calculation/function) logic
- Substring and byte shifting
- Data type conversion
- Custom function
The decision criteria for which protection function to use for each datum are:
- Security - how strong (uncrackable) must the function be
- Reversability - whether that which was concealed must later be revealed
- Performance - how much computational overhead is associated with the algorithm
- Appearance - whether the data must retain its original format after being protected
IRI is happy to help you assess which functions best apply to your data.
Note also that you can protect one or more fields with the same or different functions, or protect one or more records entirely ("wholerec"). In each case, the condition criteria and targets/layout parameters can also be customized, and combined with data transformation and reporting in the same job. And, in fit-for-purpose multi-table wizards, or through global data classification, DBAs and data stewards can apply these protections as rules to preserve consistency and referential integrity database or enterprise wide.
Both! FieldShield and CoSort's SortCL program give you the ability to protect both kinds of data sources simultaneously with one or more field-level security functions. These IRI products can address either source type in bulk (static data masking) or surgically (dynamic data masking) through filter command or customized stored procedure calls.
Of course, some databases have built-in column encryption. But their approach may be cumbersome or limiting for a variety of reasons, such as:
- You need to protect multiple databases other sources or data in motion, like flat files and a single platform or method will not address, or be compatible with, enterprise needs
- Built-in DB encryption libraries may also be too slow, costly, or complex to implement
- They are limited to a single encryption methodology that may or not conform to security or appearance requirements
- You may also need to leave your data as-is while it's in the database, but protect it while it's moving into or out of the database. That's where flat files come in. Data is often in a flat file format as it goes in or out of your databases.
Other encryption products protect an entire file, database, disk, computer, or network to protect sensitive data moving through your systems. However, encrypting more than the fields that matter can take a long time, and cut off your access to the non-sensitive data that still needs to be accessed and processed. FieldShield and CoSort's SortCL can encrypt (or otherwise protect) only those fields/columns that need it, and can do it in the same job scripts and I/O passes with big data transformation, migration, and reporting.
How can your product(s) mask data in MongoDB?
For MongoDB, FieldShield or DarkShield can find and mask sensitive data in different ways, depending on which fits your use case best. Note that DarkShield can handl both cases below. But more specifically,
if all the data in the collections is all strutured:
- 1st Method: FieldShield w/CSV export & import
- 2nd Method: FieldShield w/CData O/JDBC drivers
- 3rd Method: FieldShield w/IRI BSON driver
or, if your collection(s) also contain semi-structured (JSON) or unstructured (document, image, free text, etc.):
- 4th Method: DarkShield GUI
- 5th Method: DarkShield API
How does your product compare with MS SQL TDE (Transparent Data Encryption)?
How does your product compare with the Oracle Data Masking & Subsetting pack?
| Feature | Oracle Data Masking & Subsetting Pack | IRI FieldShield / Voracity | Reference URLs |
| Automatic Discovery of Sensitive Data and Relationships | Application Data Modeling automatically discovers columns from Oracle Database tables containing sensitive information based on built-in discovery patterns such as national identifiers, credit card numbers, and other personally identifiable information. It also automatically discovers parent-child relationships defined in the database. | The IRI Workbench graphical IDE, built on Eclipse, front-ends all data discovery -- DB profiling (which includes statistical information, integrity checking, and value searching), schema-wide PII searching and classification, and ER-diagramming functions for Oracle and other RDBs through IRI FieldShield. We are also working to implement machine-learned, NLP modeled named-entity recognition, which is already part of IRI DarkShield for PII search/mask ops for unstructured data. | https://www.iri.com/products/workbench/fieldshield-gui/profile |
| Extensive Masking Format Library and Application Templates | Centralized, extensive and customizable library of predefined masking formats such as national identifiers, credit card numbers, and other personally identifiable information facilitates ready-to-go masking formats. Downloadable masking templates for select versions of Oracle E-Business Suite and Oracle Fusion Applications further simplify the task of defining masking rules. | Same, and more. IRI users can select and re-use provided or custom-defined patterns for multiple NID, credit cards, phone numbers, and other data formats for searching, classification, masking, and prototyping purposes They can also make use of provided or custom-written test data generation functions to produce computationally valid NIDs. While it does not have downloadable templates specifically for Oracle, FieldShield users can define their own formats, and choose from 14 different categories of data masking functions (or "roll their own), and apply them every version of Oracle. | https://www.iri.com/solutions/data-masking/static-data-masking AND https://www.iri.com/products/workbench/data-sources |
| Comprehensive Masking Transformations | Comprehensive masking transformations caters to different masking use cases such as masking based on a condition, generating consistent masked outputs for a given input and more. | IRI FieldShield provides more data masking functions (see URL above), and preserves consistency and referential integrity capabilities using ad hoc or stored rules matched to pattern-matched column names or pattern/value-matched data classes. In addition, IRI Workbench supports more job design and management options, along with compatible data management jobs in the same free Eclipse pane of glass. | https://www.iri.com/products/workbench/fieldshield-gui/apply-rules AND https://www.iri.com/products/workbench |
| Multi Factor Subsetting | Sophisticated subsetting techniques facilitate generating subsets of data based on goals such as percentage of database size and percentage of rows in a table or based on conditions like region, time, department and more. | A database subsetting wizard is included with IRI Voracity subscriptions which automatically creates referential correct, masked or unmasked subsets of any connected database schema. Conditions can be tailored in dialogs during wizard generation or in the scripts. In addition, robust test data generation (from scratch) with all kinds of realistic conditions can be custom-defined. | https://www.iri.com/solutions/test-data/db-subsetting AND https://www.iri.com/solutions/test-data#techniques AND https://www.iri.com/blog/test-data/making-realistic-test-data-production/ |
| Fast, Secure and Heterogeneous | Masking and subsetting can be performed on a cloned copy of the original data, eliminating any overhead on production systems. Alternatively, masking and subsetting can be performed during database export, eliminating the need for staging servers. Masking and subsetting can be performed on data in non-Oracle databases by staging the data in an Oracle Database using the relevant Oracle Database Gateway. | The same, and more. Masked (or subset) targets are usually sent to alternative target tables, which can be created in IRI Workbench, that same pane of glass built on Eclipse for all IRI job design which also serves for cross-DB administration. Actual cloning and masking is also available by tying FieldShield masking jobs into Commvault or Actifio-driven Oracle DB snapshots. And, IRI Voracity users can do data transformation, migration, and cleansing in their masking jobs. | https://www.iri.com/solutions/data-integration/etl AND https://www.iri.com/blog/data-transformation2/creating-executing-sql-statements-in-iri-workbench/ AND https://www.iri.com/ftp9/pdf/FieldShield/Actifio-FieldShield-DBClones.pdf AND https://documentation.commvault.com/11.20/configuring_third_party_data_masking_for_oracle_database_clones.html AND https://www.iri.com/news/newsletters/4th-quarter-2019 |
| More supported static data masking functions to choose from, including custom-defined functions | https://www.iri.com/solutions/data-masking/static-data-masking | ||
| Ability (via DarkShield) to classify, search, and mask inside unstructured (LOB, XML, JSON, CSV, PDF, free text, image) columns inside RDBs like Oracle, too, using the same data classes and masking functions! | https://www.iri.com/blog/data-protection/darkshield-relational-databases/ | ||
| Fit-for-purpose job creation wizards for automatic single- multi-source masking jobs and work flow generation | https://www.iri.com/services/training/courseware#governance | ||
| Multiple job design, modification, execution (deployment), and sharing options | https://www.iri.com/services/training/courseware#workbench AND https://www.iri.com/blog/iri/iri-workbench/introduction-metadata-management-hub/ |
||
| Data classification wizard that incorporates search and masking rule matchers | https://www.iri.com/blog/data-protection/classify-mask-pii-in-databases-with-fieldshield/ | ||
| Database profiling and table or schema-wide PII search | https://www.iri.com/products/workbench/fieldshield-gui/profile | ||
| Flat-file data profiling and PII search | https://www.iri.com/blog/iri/iri-workbench/flat-file-profiling/ | ||
| Dark data PII (unstructured file) search and reporting | https://www.iri.com/blog/migration/data-migration/unstructured-data-data-restructuring-wizard/ | ||
| Automatic application of data masking functions to data classes, table- or schema-wide | https://www.iri.com/products/workbench/fieldshield-gui/apply-rules AND https://www.iri.com/blog/data-protection/applying-field-rules-using-classification/ AND https://www.iri.com/blog/iri/iri-workbench/schema-pattern-search-data-class-association/ OR JUST https://www.iri.com/blog/data-protection/classify-mask-pii-in-databases-with-fieldshield/ | ||
| Support for ~ 160 data sources, including relational, file, NoSQL, cloud, big data, unstructured data, etc. | https://www.iri.com/products/workbench/data-sources | ||
| Fit-for purpose re-ID risk scoring and reporting wizard, plus additional data masking (blurring and bucketing) functions to further anoymize quasi-identifying data in otherwise masked sets, with training and certification services optionally available | https://www.iri.com/solutions/data-masking/hipaa AND https://www.iri.com/solutions/data-masking/hipaa/risk-score AND https://www.iri.com/solutions/data-masking/static-data-masking/blur AND https://www.iri.com/ftp9/pdf/FieldShield/HIPAA_Data_Certification_Course_Outline.pdf | ||
| Structurally and referentially correct test data generation (from DDL info only) and population via built-in RowGen functionality | https://www.iri.com/solutions/test-data AND https://www.iri.com/products/rowgen | ||
| Fully compatible metadata and job integration with other data management (ETL, migration, analytics, data quality, etc.) operations in the IRI Voracity platform's Eclipse IDE, IRI Workbench | http://www.iri.com/products/cosort/sortcl-metadata AND http://www.iri.com/products/voracity/technical-details#capabilities AND https://www.iri.com/products/workbench | ||
| Software development kit (SDK) for API-level integration of masking functions in bespoke applications, for dynamic data masking, etc. | https://www.iri.com/blog/vldb-operations/fieldshield-sdk-2/ | ||
| Real-time use of API mask functions in triggers for inserts, etc. | https://www.iri.com/blog/data-protection/real-time-data-masking/ | ||
| Proxy-based dynamic data masking, access control and SQL activity auditing for multiple databases. | https://www.iri.com/blog/data-protection/proxy-dynamic-masking-fieldshield/ | ||
| Ability to run many of the same masking functions in Hadoop, interchangeably (without modification to FieldShield job scripts) in MapReduce 2, Spark, Spark Stream, Storm or Tez | https://www.iri.com/solutions/big-data/hadoop-optional | ||
| Masking functions and IRI Workbench UI shared with sister products (also included in Voracity subscriptions): IRI CellShield EE for masking data in Excel, and IRI DarkShield for masking data in unstructured text files, Office & .pd's, images, faces, NoSQL DBs, etc. | https://www.iri.com/products/cellshield/cellshield-ee AND https://www.iri.com/products/darkshield |
After you find and classify PII in the free IRI Workbench IDE (built on Eclipse) for FieldShield, Voracity, etc., you can declare ad hoc and/or rule-assign specific field-level protection functions in FieldShield or other SortCL-compatible jobs. These static data masking functions provide field-protected views of sensitive data (like social security or phone numbers, salaries, medical codes) in ODBC-connected database tables and sequential files, through some 14 different categories of techniques, which include:
- field filtering (removal)
- string manipulation or masking (redaction)
- quasi-identifier generalization
- secure encryption and decryption
- reversible and non-reversible pseudonymization
- ASCII de/re-ID, encoding, and big shifting
and it is through the consistent application of these functions (on the basis of data classes or pattern-matched column name rules) that preserves referential integrity. Other ways to protect data and preserve referential integrity in Voracity in addition to persistent data masking is through the built-in database subsetting wizard (where masking functions can also be applied) or through structurally and referentially correct synthetic test data generation through the (IRI RowGen) DB test data job wizard. See the links here.
Yes. You can also use FieldShield to remove (redact, omit, or delete), or randomize (random generation or value selection to replace) PII at the column or row level as options, instead of obfuscating it (via encryption or blurring, for example). The target of that job can be new tables with the same structure in another schema you can create, build, and load from IRI Workbench, which is as much a cross-platform DB administration environment as much as it is the IRI tooling environment.
Does the software support in-place masking, or only from source to target?
Both, though the latter is more common. For in-place, just declare the target to be the source. We recommend doing that only after testing the output (e.g., via a small test file or stdout), to make sure it's what you want in terms of format/appearance and functionality (e.g., reversibility via decryption) if you have no backup.
What happens if a masking operation fails due to a schema constraint?
Failures are logged with reasons. Adjust the rule to be format preserving or schema compliant, then rerun Mask Only using the previous annotations to remediate without re-scanning.
Can I apply data masking functions to BI/DW tasks or tools?
Yes, simultaneously. In fact, the IRI CoSort product (via its SortCL program) or the IRI Voracity (big) data management platform (via SortCL or interchangeble Hadoop engines) can enforce field-level security in the course of data integration, data quality, and reporting jobs. In other words, you can in the same product, program, and I/O pass: mask/redact, encrypt, psedonymize or otherwise de-identify PII values while transforming, cleansing, and otherwise remapping and reformatting the data from heterogeneous data sources.
Legacy ETL and BI tools cannot do this as efficiently or as affordably. In fact in Voracity -- which supports and consolidates data discovery, integration, migration, governance, and analytics -- you can process (integrate, cleanse, etc.), protect (mask), and present (report/analyze) or prepare (blend/munge/wrangle) data all at once.
Alternatively, you can run IRI data masking programs on static data sources (or call our API functions dynamically) just to protect certain fields that your existing platform will then transform or visualize. In this way, you can:
- use your existing code
- protect only the fields needing security
- keep both protected and unprotected data available to the routines and systems that need to access it.
What methods can I use to mask data in NoSQL DBs like MongoDB, Cassandra, or ElasticSearch?
There are several, but start with the latest described in this article:
Masking PII in MongoDB and Cassandra with DarkShield: 4th IRI Method
Invocation options are flexible, and storage usage could be an issue if you are writing masked targets backed to limited SharePoint storage, that too is not required (i.e., the targets can also be local or other cloud stores like Azure Blob). You can thus schedule or run the configured jobs ad hoc to run from the GUI, CLI or API call.
For CellShield, how do I know if I need the 32- or 64-bit version?
It depends on the version of Excel (not your O/S) that is running.
How can I tell whether I'm running a 32-bit or 64-bit version of Microsoft Office?
The CellShield COM plug-ins for Excel must match the version of Excel you have. The steps to check the version of Microsoft Office you are using are as follows:
-
Start a Microsoft Office program (Word, Excel, Outlook, etc.).
-
Click the File tab in the ribbon.
-
Select Help in the left column (Or Account if you are using Office 2013 or newer. If using Outlook 2013, click Office Account).
-
Find the section called About Microsoft [Program Name] in the right column. (Select the About [Program Name] icon in Office 2013 or newer)
-
Review the version information (e.g., Microsoft® [Program Name]® (15.0.4771.1000) MSO (15.0.4771.1001) 32-bit) on top of the new window to determine whether you are using a 32- or 64-bit version.
NOTE: You may not necessarily be using a 64-bit version of Microsoft Office even if you are using a 64-bit version of Windows XP, Vista or Windows 7-11.
DarkShield is a local app, do you plan to make it SaaS in the future?
IRI will provide a web application to supplement or "eclipse" the current thick client, IRI Workbench but is unlikely to ever provide software in hardware infrastructure which IRI controls. This is because IRI customers want control over their data and IRI does not want the liability of storing it, nor the price hikes from SOC2 or FedRAMP certifications (which are available from cloud vendors which could host the solution anyway). You can already treat IRI software today as a rudimentary SaaS technically via VM or RDP hosting in your cloud (including the DarkShield API in a container), and commercially through a pay-go subscription. In addition, the DarkShield V7 release will support more granular volume-based license fees for all source types.
What are the DarkShield service parameters for determining server resources?
DarkShield service parameters themselves do not determine the resources, so this will depend on how you set up the tool, and particularly where you host the API. DarkShield performs well and linearly in volume (for files), and also supports load balancing across multiple nodes per this example (where the proxy may determine things). There are some minimum resource recommendations for IRI software generally in this FAQ.
No data is transmitted from the CellShield plugin. And no connection is made or needed by CellShield or any other IRI PII discovery or static data masking product.
How robust is your encryption?
FieldShield, CellShield, and DarkShield (as well as CoSort) and thus Voracity, ship with multiple 128 and 256-bit encryption libraries using proven, compliant 3DES, AES, GPG and OpenSSL algorithms. For each PII item or sub-string, you can use the same or different built-in encryption routine, or link to your own encryption library and specify it as a custom, field-level transformation function in a job script. You can also use the same algorithm(s) and a different encryption key for each field as well.
Encryption key management is supported through passphrases in job script, secure files, and environment variables, as well as in third-party vaults like Azure Key Vault and Townsend Alliance Key Manager.
Who has access to masking jobs is usually a matter of software and job distribution. Consider control over IRI projects or jobs in Git for example as one method. Admin or end-user on-demand masking can occur from the(ir local) desktop) GUI, a prepared CLI command or third-party program calling the CLI or API directly ... the controls for which can thus be a system administration function in s shared environment (i.e., who gets access to GUI and API ). In the more typically distributed environments, the DarkShield API can be located on the same computer with IRI Workbench, on another Windows or Linux system, or in a Linux container, on-premise or in the cloud. That supports role separation as a network administration function. The future web app roadmap contemplates finer role separation / job governance support from within (a more self-contained portal for this if you will) as well.
What about auditing these activities?
All FieldShield and CoSort/SortCL job scripts and field-level functions can be recorded in XML audit logs that you can secure, and query with your preferred XML reporting tool. You can also use SortCL scripts (n.b. samples are provided, where /INFILE=$path/auditlog.xml /PROCESS=XML, etc.) against these audit logs for reporting. See https://www.iri.com/solutions/data-governance/verifying-compliance for more information.
In CoSort 11, an even more robust JSON audit log can be generated according to an operational governance policy, and queried through an data wrangling tool to export and analyze specific job information.
IRI DarkShield produces multiple logs for searching and masking operations. See https://www.iri.com/products/workbench/darkshield-gui/audit-logs for more information.
Besides the IRI masking tool search and audit reports, can I export that info to a SIEM?
Yes, to Splunk for example, in multiple ways. See articles like these:
- Revealing Data Profiling Secrets in Splunk
- Automatically Forward Target or Log Data into Splunk
- Shedding Light on Dark Data with Splunk ES
+ Data Governance > Data/Metadata Forensics & RBACs
Does IRI software support RBAC?
Yes, in multiple ways, including access permissions to job metadata, data sources (and targets), and decryption keys, and via differential data class function/rule assignments. See the other questions in this section and contact fieldshield@iri.com or voracity@iri.com for assistance setting up your controls.
Can we set up users and assign privileges to them in IRI Workbench?
Since there is no "Voracity", "FieldShield", or "CoSort" server per se, there is currently no place to configure users. Users are identified by their login to either the PC where they run IRI Workbench, or the remote server that runs the job (i.e., where SortCL is installed). Either way, it is the operating system (OS) that controls the user, not IRI software.
When it comes to reading and writing files, the OS determines who has access to files based on the user under which the job scripts run. For databases, the userid and passwords or other credentials are entered into the JDBC and ODBC connection strings used to connect to the database.
The Workbench artifacts in the workspace can also be protected if they are shared through a Git, or other, source control repository. In this way, passwords or encryption keys can be used to control who can read and write the job scripts, metadata files, set files, and other assets in the workspace.
This is a different paradigm than most other ETL and data masking products, where all database connections are maintained on one central server. While our architecture takes a little getting used to, especially when coming from another type of tool, we feel that it provides a lot more flexibility in operation.
Our latest platform release (OGS in CoSort 11) suports even more granular system of user and data governance through RBACs for specific IRI jobs, functions, and data classes.
A future web-based UI will allow IAM and logging policies to be control access to it and the back-end engines according to governance policies and user groups specified and/or integrated with ActiveDirectory or LDAP.
Yes. In the context of IRI Voracity, CoSort, FACT, NextForm, or IRI FieldShield and RowGen operations, data and metadata can be role-segregated via:
- DBA-defined source/target data accesses (configuration details for which are stored in manageable DSN files or Workbench Data Connection Registry settings subject to workspace access permissions controlled at the file (or O/S log-in) level
- Active Directory (A/D or Entra ID) or LDAP (O/S)- and/or repository (e.g., Git)-controlled access to data files, workspaces, projects, data and job metadata, executables, logs, etc. or to FieldShield or DarkShield encryption keys managed through a key manager like Azure Key Vault.
- The new IRI Operational Governance System (OGS) / runtime infrastructured introduced in 2026 and focused initially on the IRI back-end data processing program, SortCL, which uses a central Policy File to define users, groups and roles for access to job-specific attributes including data sources, scripts, and logs.
- IRI DarkShield components including its current GUI in IRI Workbench, job configuration or API/CLI spec files, logs, and the API engine itself, can also be controlled as O/S level assets subject to differential permissions and A/D bindings. In 2027, IRI will introduce a browser-based front-end with SSO to allow the assignment of differential accesses (and repository-based role definitions) to various assets/entitlements.
How do you control access to the product based on roles?
Through client computer or ActiveDirectory/LDAP imposed access controls and file-level permissions. Beyond that, either the erwin (AnalytiX DS) governance platform or any Eclipse-compatible SCCS like Git for metadata assets -- where permissions by role are configurable -- can lock down specific projects, jobs, and other metadata assets.
Can users be assigned multiple roles?
Yes, Multiple roles/permissions for IRI FieldShield or Voracity (etc.) metadata assets (ddf, job scripts, flows) etc. can be assigned through system administators assigning policy-driven ActiveDirectory or LDAP objects to those assets. Other options include the erwin data governance platform (premium option) or Eclipse code control hubs like Git; see http://www.iri.com/blog/iri/iri-workbench/introduction-metadata-management-hub/ for an example.
The IRI Test Data Hub within the ValueLabs TDM portal also supports the designation and deletion of Administrator and Tester roles. The highest level administrator can also delegate security policy approval permissions to other administrators. Such role permissions are set at very fine-grained individual or group levels controlling DB log-in, execution authority, data access, and audit log query/report/restore privileges.
Yes, In the context of IRI Voracity (for profiling, ETL, DQ, MDM, BI, etc.), CoSort (for data transformation), FieldShield (for PII discovery and masking) , NextForm (for data migration, remappping and replication), and RowGen (for TDM and subsetting), access to specific data source (and targets, down to the column level) can be controlled through DBA-granted or file-level permissions (managed in DSN files and the IRI Workbench data connection registry), as well as through field-level revelation authorizations controlled in (securable) job scripts and decryption keys.
In the context of IRI DarkShield, accesses to relational and NoSQL databases is restricted through connection-specific protocol (JDBC driver configurations or API keys for example) configurations. File sources are subject to local O/S or cloud-API-key based permissions. Roles for each are currently defined through paradigms like Active Directory applied individually as an authentication method for a database, or binding to a file. In a future web-based front-end for DarkShield, SSO management will additionally respect pre-configured RBACs for data source accesses at the user level.
Both, inasmuch as data, metadata, and/or job script access -- plus execution permission -- are associated with ActiveDirectory object-defined, DBA login, and/or file-system controls imposed on a policy basis for authentication purposes.
Calling applications can also impose additional layers of user authentication to optionally fill a gap or protect additional data touchpoints.
+ DW ETL Operations
Voracity is a modern one-stop-shop for rapidly managing and leveraging enterprise data. It is also a standalone ETL and data life cycle management platform product that also packages, protects, and provisions many forms of big data in production and test data for DevOps.
Voracity saves money on software, hardware and consulting resources, while expanding your enterprise information management (EIM) capabilities in support of digital business initiatives -- all from one Eclipse pane of glass.
All the features/functions listed below are supported in the IRI Voracity data management platform and constituent IRI Data Manager and IRI Data Protector suite products (excect FACT which is supported but comes at a premium). Refer to the Components here.
GUI refers to the IRI Workbench Graphical User Interface. IRI Workbench is a free Integrated Development Environment (IDE), built on Eclipse,™ for designing and managing the jobs which integrate and transform data through the SortCL program in Voracity, IRI CoSort, and all other IRI software.
DTP refers to the Data Tools Plugin (and Data Source Explorer) in the IRI Workbench. DDF refers to Data Definition Files, the metadata for source and target data layouts.
We already spent a fortune on our ETL tool. Can you just help use run its jobs faster?
We understand that, and have been accelerating jobs in legacy ETL tools (especially Informatica and DataStage transforms) for years. To accelerate third-party ETL and BI/analytic tools, as well as DB operations, use IRI's scriptable, batchable transform engine(s) alongside -- and amplify the return on your investment in -- these platforms:
- ETL Tools
- ETI Solution
- IBM DataStage
- Informatica PowerCenter
- Microsoft SSIS
- Oracle Data Integrator
- Pentaho Data Integrator
- Talend
- BI Tools
- BIRT
- BOBJ
- Cognos
- Excel
- MicroStrategy
- QlikView
- OBIEE
- Analytic Tools
- JupiterOne
- R
- SAS
- SpotFire
- Splunk
- Tableau
- Databases
- DB2
- Greenplum
- MySQL
- Oracle
- SQL Server
- Sybase
- Teradata
Run "SortCL" program jobs in the IRI CoSort package or IRI Voracity platform from your tool's command-line (shell) option to prepare big data faster, and populate the DB tables or file formats your tool can directly ingest.
Use the same high-performance data movement engines that Voracity can: IRI FACT for extraction, IRI CoSort (or Hadoop) for data transformation, IRI NextForm for data/DB migration and replication, IRI FieldShield for data masking, and/or IRI RowGen for generating test data.
Can we replace our legacy ETL tool automatically?
Yes, now you can. Voracity is API-integrated with AnalytiX DS metadata hub technology so you can convert from legacy ETL products more or less automatically and affordably.
Contact your IRI or AnalytiX DS representative and ask about CatFX templates for Voracity from your current ETL tool, along with any LiteSpeed Conversion services you need to help port and test the more complex mappings.
Whether you are switching ETL platforms or just starting out in data integration, use Voracity to shrink time to deployment and information delivery.
Why should I consider IRI Voracity? What does Voracity offer that others don't?
Some of the things that Voracity offers that legacy and open source ETL (much less ELT) tools do not are:
- Built-in data profiling tools for flat-files, databases, and dark data (unstructured) document sources
- Raw power and scalability with or without Hadoop; i.e., built-in performance in volume, but also seamless support for Hadoop!
- A negligible learning curve: simple, explicit, accessible, and open text metadata you can easily use, modify and share
- The ability to deploy jobs outside the GUI, running them via command line, batch, or any program via system or API call
- An open source GUI you already know (Eclipse) that front-ends proven, robust manipulations and reports on big structured data
- Advanced aggregation functionality like lead/lag, ranking and running, multiplication and expressions
- Multiple nested layers for both conditions and derived fields with support for PCREs, fuzzy matching, C (math/trig) functions, locale and 'conversion specifiers', etc.
- Composite data value definition for both production data (format masking) migration and test data generation
- Built-in: data and DB profiling, migration, replication and administration
- 12 field protection (static data masking), DB subsetting, and synthetic referentially correct test data generation
- Data-centric change data capture, slowly changing dimension and detail and summary reporting, plus trend (predictive analytics), and web log (clickstream analytics) reporting
- Seamless metadata integration with Fast Extract (FACT) for major RDBs, plus Hadoop, AnalytiX DS and MIMB-embedding platforms
- Superior price-performance, fast ROI, and immediate access to US-developer support
Another way to consider the differences is by looking at what Voracity's does not require, and why:
With Voracity, there is no need for: |
Because Voracity: |
|---|---|
| separate transforms or transform stages | can combine filter, sort, join, aggregate, pivot, remap, custom and other transforms in the same job script and I/O pass, though it can represent and run them separately in separate task blocks |
| partitioning, manual or otherwise | automatically multi-threads and uses other system resources only your resource controls limit, and does not push transformations into the database layer where there are inherently less efficient |
| manual metadata definition | provides automatic metadata discovery and format conversion tools, and is supported by AnalytiX DS Mapping Manager and CATfx templates, as well as MITI's MIMB platform |
| separate BI (reporting) tools | can produce custom-formatted details and summary reports in the same job script and I/O pass with all the transforms, and/or hand off data to files, tables, or ODA streams in Eclipse for BIRT |
| separate data masking tools | includes every single function in FieldShield, the most robust data masking and encryption tool available. |
| separate test data tools | all the functions of RowGen, which can generate safe (no need for production data), intelligent (realistic and referentially correct) test data for DB, file, and report targets |
| long-term consulting | uses an already familiar Eclipse GUI and metadata defining both data and ETL processes |
| separate MDM hubs or data quality tools | has a wizard for MDM, plus support for: composite data type definitions, master data value lookups, joins, tables and set files suitable for production or test data |
| a new team sharing or version control paradigm | metadata repositories and job scripts work with any source code and metadata version control system, including AnalytiX DS and GIT, CVS or SVN in Eclipse |
| concerns about open source or support | is backed by IRI, a stable 38-year-old company with more than 40 international offices |
| a huge budget now, or a lease renewal headache later | is sold at affordable prices for perpetual or subscription use |
Yes, CoSort is a data transformation, and thus, ETL engine. It is not a traditional ETL package however, but the IRI Voracity that leverages CoSort for data transformation is. Voracity can use CoSort as well as Hadoop for transformations, and of course FACT for extraction and pre-sorted bulk loads into auto-config'd DB load utilities. Refer to:
http://www.iri.com/solutions/data-integration/etl
and
http://www.iri.com/products/voracity
When you use Voracity or CoSort, you benefit from high-performance (I/O-consolidated, multi-threaded) Transformations like:
- filtering
- sorting
- joining
- aggregation
- conversion
In addition, CoSort -- and in particular, its Sort Control Language (SortCL) program -- can also handle:
- slowly changing dimensions
- fuzzy logic lookup tables
- pivoting (normalization and denormalization)
- running, ranking, and windowed aggregates
- bulk/batch change data capture
In Voracity, much of the above is exposed in graphical wizards, specification dialogs, workflow and transform mapping diagrams so you don't need to learn how to script those jobs. The jobs can be previewed and then run (scheduled) from the GUI, or on the command line (and thus in batch scripts and other applications, as well as third-party ETL tools that need a boost). Metadata can be change-tracked, shared, secured, and version-controlled in repositories like EGit on-premise or in the cloud.
Does CoSort work with other ETL tools or tasks?
Yes, both. As far back as 1999, industry experts have been touting CoSort as an ETL engine for its high-performance data staging and integration capabilities. CoSort - and it's SortCL program in particular - performs the heavy lifting of selection, transformation, reporting, and pre-load sorting against sequential files in an ODS, DW staging area, or on extracted tables in suspense.
CoSort's SortCL is a push-down optimization option for Informatica PowerCenter, and in the sequential file stage of IBM DataStage, to perform faster, combined (single-pass) sort, join, and aggregation operations. Click here to read the press release about CoSort's 6x improvement of Informatica speed.
Besides proven integrations with, and plug 'n play sort replacements for, DataStage and Informatica, CoSort also links to Kalido, ETI, SAS and TeraStream ETL packages. CoSort's SortCL programs can be called as an executable from any tool allowing that as well, which would also mean Ab Initio, Pentaho, JasperETL, Pervasive DataRush, Hummingbird, and others, to further consolidate and optimize data transformation performance via the file system.
Can we use CoSort or Voracity with DataStage?
Yes. Either through the DataStage sequential file stage or Before-Job Subroutine. With or without the larger Voracity ETL and data management platform subscription supporting CoSort, you would use CoSort as an external data transformation hub, combining large sort, join, aggregate, reformatting, protection, and cleansing functions in a single job script and I/O pass in the file system. Voracity adds the visual ETL design environment and Hadoop execution options around CoSort.
For more information, please see:
http://www.iri.com/solutions/data-integration/etl-tool-acceleration/datastage
You can also leverage AnalytiX DS technology to automatically convert most ETL jobs currently in DataStage to Voracity:
http://www.iri.com/solutions/data-integration/replatform-etl
Can we use CoSort or Voracity with Informatica?
Yes. With or without the larger IRI Voracity ETL and data management platform subscription supporting IRI CoSort, you can use CoSort as an external data transformation hub, combining large sort, join, aggregate, reformatting, protection, and cleansing functions in a single job script and I/O pass in the file system, and just call those jobs into existing Informatica job flows as a command line operation. Voracity adds the visual ETL design environment and Hadoop execution options around CoSort.
For more information, see:
http://www.iri.com/blog/data-transformation2/informatica-pushdown-optimization-with-cosort/
You can also leverage AnalytiX DS technology to automatically convert most ETL jobs currently in PowerCenter to Voracity:
http://www.iri.com/solutions/data-integration/replatform-etl
There are two third-party technologies designed for, and tested to be compatible with your existing tools and ours, which help:
1) AnalytiX DS Mapping Manager or LiteSpeed Conversion processes migrate legacy ETL jobs to equivalent Voracity ETL jobs. Voracity ETL jobs are powered by the CoSort SortCL program or interchangeable Hadoop engines mapped the same way. This includes both source and target data layout specifications, and most transform mappings. Manual translation and testing services fill in the gaps for complex mappings that do not auto-convert.
2) For only converting the data layouts in another ETl (BI, modeling, and DB) tool to SortCL layouts, you could also use the Meta Integration Model Bridge (MIMB) to convert Informatica .xml, DataStage .DSX and other third-party tool metadata to CoSort SortCL DDF.
We use CoSort already, so don't we already have Voracity?
Yes, to a degree.
Voracity's core data manipulation features -- transformation, mapping, masking, and embedded report formatting -- are all built into the SortCL program you can already script and run with your CoSort license to do those things. And, the GUI for CoSort (IRI Workbench, built on Eclipse), is the same GUI Voracity and all subset IRI products in the IRI Data Manager (CoSort, FACT, NextForm) and IRI Data Protector (FieldShield, CellShield EE, RowGen) suites use! With that GUI comes access to a lot of Voracity features through the toolbar menu, like data discovery, ETL flow diagrams, MDM wizards, FieldShield data masking and RowGen test data generation wizards. So you could run a lot of those jobs with your existing SortCL license.
As a CoSort licensee, however, you are only entitled to IRI support for the feature-functions documented in the CoSort manual (and in particular, the SortCL language reference chapter), and for GUI operations based on jobs created from wizards in the "CoSort" (stopwatch icon) and "IRI" menus in the IRI Workbench toolbar. That is, you would normally be confined to the materials for CoSort users in the Welcome section and support content for CoSort in the help menu.
Voracity subscribers, on the other hand, are entitled to support from IRI for all the feature-functions and menu items exposed in the IRI Workbench GUI, including data profiling, masking, test data, ETL, MDM, CDC, slowly changing dimensions, metadata management, and BIRT integration. Voracity users can also get IRI support on optional upgrades with Voracity-compatible software like AnalytIX DS Mapping Manager, IRI FACT, running SortCL jobs in Hadoop, predictive analytic reports using SortCL and BIRT, and the Paques self-service, shard-powered BI module.
For a complete list of the available features and support provided with all IRI software, please refer to this comparison page.
CoSort's SortCL program has built-in filtering and selection logic to reduce bulk, segment, and scrub data during or after processing.
For more advanced data cleansing and quality operations, SortCL allows you to plug in your own function libraries to perform custom transformations at the field level, before or after sort, join, merge, or report processing. SortCL ships with a sample template: a Melissa Data address standardization object that cleanses the address field as records are output.
For more information, see:
CoSort SortCL, IRI Voracity, and other IRI software programs (including FACT, NextForm, FieldShield, and RowGen) can all run from the command line and thus be scheduled into batch streams with cron, Stonebranch Universal Controller (UAC), Cisco TES, CA Autosys, ASCI ActiveBatch and similar applications. PoCs were done with Oracle DBMS_Scheduler and UAC and Full 360 metaController. See:
http://www.iri.com/blog/iri/iri-workbench/stonebranch-universal-controller-integration/ and
http://www.iri.com/blog/data-transformation2/automate-iri-data-integration-jobs-oracle-job-scheduler/
From within the IRI Workbench -- the free Eclipse GUI supporting all IRI software -- a Task Launch Scheduler is built in. See:
http://www.iri.com/blog/iri/iri-workbench/scheduling-jobs-in-iri-workbench/
+ Flat Files
What do practitioners say about this?
Apart from the many data warehouse architects who use CoSort's SortCL tool and find its flat-file approach faster than SQL procedures and ETL tool steps, many experts also acknowledge the efficiency of flat-files in high volume data staging:
"The first system for which the data warehouse is responsible is the data staging area, where production data from many sources is brought in, cleansed, conformed, combined, and ultimately delivered to the data warehouse presentation systems ... The two dominant data structures in the data staging area are the flat file and the entity/relationship schema, which are directly extracted or derived from the production systems."
from "The Foundations for Modern Data Warehousing" by Ralph Kimball, appearing in Intelligent Enterprise Magazine's Data Warehouse Designer Section.
Why does CoSort rely on flat files? Why should I?
By using flat files, the SortCL program -- which is the primary utility in the IRI CoSort product and default engine of the IRI Voracity data management (and integration) platform -- bypasses the normal overhead of DB connectivity and transformations. SortCL even flattens FDB tables connected through ODBC and the data in semi-structured sources like MongoDB and JSON files. This helps move the engine through rows of data sequentially and consistently, while simultaneously exploiting the asynchronous I/O, advanced memeory management, and multiple-threads available from the O/S; i.e., it doesn't use Java programs, either.
The flat structure it's processing also allows the tool to rapidly combine data transformation, reporting, protection and prototyping functions in the same job and I/O pass. Thus with SortCL, you can simultaneously filter, cleanse, standardize, transform, mask, and report on massive collections of data. Compare this kind of task consolidation potential with how you get work done now, particuarly against multi-step ETL tools which are not only inefficient by virtue of the multiple steps they have to configure, but also run, one memory-constrained, separate I/O step at a time, and sometimes also requiring partitioning with SortCL never would.
Put another way, because of SortCL, if you use CoSort or Voracity or other SortCL-compatible products from IRI (like NextForm, FieldShield or RowGen), you can move through your data sources rapidly, and get a lot more done. So it's "one product, one place, one pass" vs. the complexity, cost and time it takes competing alternatives (multiple products, places, passes and prices).
Why is this approach more cost-effective?
Through it's Sort Control Language (SortCL) program, users of the IRI CoSort product or IRI Voracity platform can leverage the resources of their existing file systems to perform these kinds of jobs without the overhead and administrative constraints of databases and SQL procedures -- not to mention the cost of megavendor ETL tools and ELT appliances, in-memory DBs, or complex Apache projects.
Through SortCL, you can perform and combine many of these activities simultaneously against multiple data sources of any size:
- Data Transformation > select, sort, merge, join, aggregate, re-map, pivot, cross-calc, etc.
- Data Cleansing > enrich, evaluate, filter, reformat, and validate data across disparate sources
- Data Governance > manage and mask master data, manage metadata, improve data quality
- Data Migration > remap file formats, data types, endian states, record formats
- Data Replication > copy, shift, enrich, and re-purpose data from one or formats/platforms into others
- Data Federation > virtualize ad hoc mash-up views and formatted reports, or feed direct BIRT displays via ODA
- Data Masking > de-ID, encrypt, hash, pseudonymize, randomize, redact, tokenize and otherwise obfuscate fields
- Data Presentation > get 2D BI via detail, delta, and summary reports in custom formats, even with embedded HTML
- Data Franchising > filter, pivot, transform, and segment data into CSV, XML and ODBC hand-offs for BI tools
- Data Staging > scrub and prepare bulk data for other ETL tools, databases, data and spreadmarts, and analytic platforms
- Data Prototyping > generate safe, intelligent, and referentially correct DB, file, and custom-report-formatted test data
So, to process, present, protect, and prototype big data, SortCL and flat files are still the fastest, and most cost-effective approach to consolidating information lifecycle management (ILM) activities. And if you keep your data in HDFS, many of the core data transformation, masking, and test data generation functions designed in SortCL can run in MapReduce 2, Spark, Spark Stream, Storm or Tez through Voracity's Hadoop gateway (called "VGrid") without re-coding anything!
+ IRI Business
Are you CoSort or are you IRI?
The company is IRI, Inc. IRI stands for Innovative Routines International. IRI was founded in New York in 1978 as Information Resources, Inc. and changed its name during the relocation to Florida in 1995 (where the name Information Resources was already in use in Florida).
CoSort is IRI's first product and IRI is well known for it. See the products and company sections of this web site for more information on both.
We are not affiliated with another IRI -- the Chicago firm best known for retail market research called Information Resources, Inc., but ironically, they are an IRI CoSort licensee of record.
How do SortCL, CoSort, the IRI Workbench, and Voracity interrelate?
See this article. Following is a synopsis.
CoSort is IRI's best known software product for data management and manipulation. The primary operational facility and user interface in the CoSort package is the Sort Control Language (SortCL) program.
SortCL refers to both the executable and the 4GL syntax for job scripts that contain both data definition and manipulation statements. The SortCL program has given rise to several IRI spin-off products that use the same syntax for data definition, but support a lower-cost, targeted functional subset of manipulation commands. Such SortCL-compatible, fit-for-purpose IRI products include: NextForm for data migration, FieldShield for sensitive data masking, and RowGen for test data generation.
Voracity is IRI's new, "total data management" platform that includes CoSort and all the SortCL spin-off product capabilities, as well as new data discovery (profiling) tools, visual job design features for DW/BI architects, DBAs and business users, plus: Hadoop engine options, cloud and big data connectors, and data quality and MDM wizards, and multiple analytic frameworks.
IRI Workbench is the free, common Eclipse GUI for designing, deploying, and managing all SortCL-compatbile software jobs as well as all the additional functions of Voracity above.
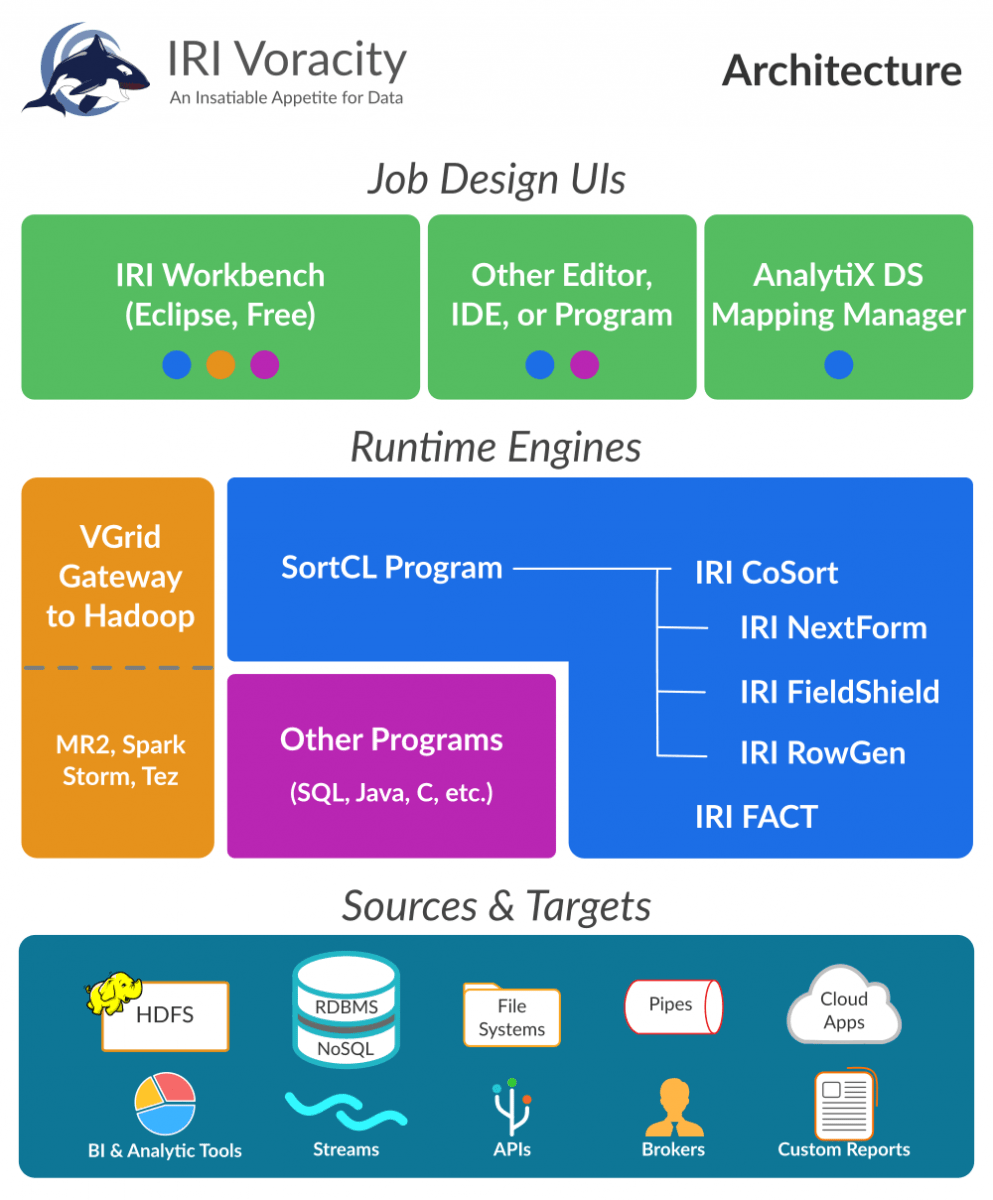
IRI does a lot, and has been around a long time. But I've never heard of you. Why?
Until relatively recently, IRI's primary focus and product line has served back-end systems that not many talk about. Doing the heavy lifting for other people's products and operations (including CGI, CSC, Cincom, Epsilon, NTT Data, Sabre, and Sungard) has made IRI more of a silent partner than the total solution provider that the company's software stack proves it to be.
In actuality, IRI is also a prominent enterprise software vendor and well known departmentally within many large companies worldwide (like American Airlines, Bank of America, Comcast, Disney, EDS, and Fidelity Investments), as well as the consultancies that serve them (like Accenture, Atos, Cognizant, DXC, HPE, and IBM Global Services). Both customers and analysts following IRI note that the company is not venture-backed and invests far more in R&D than it does in marketing, providing far more value to customers.
Gartner is following IRI software in their data integration, data masking, legacy migration, test data, and business intelligence research. IRI is also repeatedly recognized in the areas of big data (with and without Hadoop), data classification, data governance, data quality, metadata management, master data management, test data, and unstructured data.
Is evaluation free? Will you help me if it is?
Yes, and yes.
How do I get help with PoCs and implementation?
From IRI's support staff, its international representatives, and expert independent consultants. Call or email us before, during, or after your evaluation to get directed to the right resource. Because it is in IRI's best interests for your business and technical goals to be met through the use of IRI software, we will collaborate with you in the development and maintenance of successful solutions.
I don't know your products. Who will support me?
We will. So will more than 40 international support offices. And there are many third-party consultancies familiar with IRI software who can help you implement, optimize, and support applications around the tools.
More importantly, you will find it surprisingly easy to support yourself. One of the most compelling aspects of IRI software is its simplicity. All the data and job-related metadata are shared, exposed, self-documenting, and easy to modify and extend. There is also a familiar Eclipse GUI automating script creation, integration, execution, and management.
Why do IRI prices seem lower than competitors with similar capabilities?
Because they are lower. See the answer to the question above about why IRI is not as well known as those competitors.
Being part of so many other applications has not required the marketing overhead of our competitors. IRI has also chosen not to be a public company, and has not been servicing external investors or debt. Our customers continue to benefit from these savings, and we from being overwhelmed with demand that would tax our quality or service.
Directly from IRI or through an approved IRI VAR outside the Untied States who can also service our software. Call or email us for a price quote -- or use this form -- and specify the the product(s) you want to license after successful evaluation. Prices are based on what and where you run (see the pricing FAQ). IRI accepts purchase orders and credit cards.
Is 24/7 support available? Do you charge more for it?
Yes, it is available. There is normally an upcharge to standard annual support to provide 24/7 support worldwide.
What is your maintenance and upgrade policy? Are updates included?
Maintenance is free in the first year after licensing. For those users covered under maintenance, minor new releases are provided free upon request or if needed for support. Major new releases are also optional, but usually chargeable upgrades. The cost of the upgrades depends on your maintenance level.
How do I make sure my costs won't go up later?
Because you are buying a perpetual-use license, once. Support is optional and you are not forced to upgrade (even though you should eventually). If you are using Voracity on a subscription basis, however, you can lock in the license and support cost for five years through a discounted up-front payment.
+ IRI Partnerships
Do you have a partner program? If so, what types of partnerships do you recognize?
Yes in practice, but not in the onerous way of megavendor partner programs. We believe in customized reciprocal relationships that benefit our partners in these categories:
- Expert consultants who specialize in one or more industry domains and/or IT disciplines, and are in a position to recommend, refer, resell, and/or implement (service/support) IRI software;
- Industry alliances with major hardware and software manufacturers who collaborate with us on platform compatibility, reference architectures or benchmarks, and sometimes, IT analyst, media or research firms who cover IRI solutions;
- International resellers who proactively market, sell, implement, and /or service IRI software and solutions; and,
- ISVs, ASPs, MSPs, VARs, and System Integrators who embed, bundle, or refer IRI software for use with their offerings.
Is there a cost to joining your partner program?
No, except the time and energy you put into learning the software for partnership purposes, and any proactive sales and marketing efforts you choose to expend. These are not required or quantified unless territorial exclusivity is required.
How long (on average) does it take to become a partner?
This too depends on the nature of the partnership and how robust you want it to be. You can become an aware analyst or credible referral partner in half a day of study. However, it can take a few days to get paperwork signed. For those interested in reselling and embedding IRI software, the process can take days to weeks, depending on how much onboarding is required, and the timelines that initial business opportunities require.
Ask partners@iri.com for our current reseller guide to gauge the level of involvement and commitment you may want to make to learning, marketing, selling, supporting and/or custom-implementing and training on one or more IRI products.
What are the benefits of being a partner? For example: cost of licenses, etc.
- Working with a vendor stable and prudent enough to be profitable since its 1978 inception but without the pressure of outside investors or the aggravation of high turnover and incompetent / delayed support
- Relatively high margins and no fees or quotas
- De facto exclusivity in multiple geographic, industry, or technical domains
- A well integrated technology stack (using a common metadata and Eclipse GUI) to ease onboarding and cross-selling
- Fast, flexible, and fair commercial responses
You must evince sufficient technical competence, commercial viability, relevant experience and opportunities, and a good/clean reputation to partner with IRI. A specific staff size, corporate history, or certifications are not reliable indicators or requirements for success. We have found in fact that the most successful partners have core teams of just 2-3 people responsible for IRI product demos and support, sales and marketing, administration and management. Over time however, as the product and prospect opportunities grow -- and they inevitably do with effort and time -- more staff should be onboarded to service those opportunities.
What kinds of agreements or paperwork are involved in partnering?
This depends on the nature of our relationship. For example, for:
| This kind of partner ... | ... we'd expect or provide a: |
| vendor-neutral consultancy or analyst | NDA or MNDA |
| referral-only | reciprocal finder's fee MoU |
| resale | reseller agreement |
| OEM integration | royalty agreement |
Do you offer training and certification? If so, at what cost(s)?
Yes, there are multiple ways to train, and several levels of possible certification. Generally, there are no extra costs beyond our time and yours to get you oriented and on the path to self-learning. And during that process, we will also help you prepare for near-term business opportunities, or participate in prospect presentations were we are permitted and available to do so remotely. We do charge a certificate fee, but do not require certification of our partners. Those that certify however are at a distinct advantage over other channel par and in a position to sell training and support to others.
What is the price of licenses for a partner; i.e., what is the discount percentage?
This depends on the product(s) in question, the nature of your relationship with us, competitive and customer circumstances, and other factors like features and versions, special use cases, and volume discounts/incentives. Generally, finders' fee partners receive a 10% discount, whereas reseller discounts range from 25-50%. Public product price ranges can usually be found on this website, and specific pricing and transactional guidelines are in our reseller guide.
Can a partner buy licenses for their own use?
Yes, and that's required when a permanent development copy with our support is needed for the creation and maintenance of a runtime integration or solution bundle, or when one or more production licenses is used in managed service scenarios.
A free but expiring (yet long-term) license is available for a disaster recovery system for either the above, and for those proactively marketing IRI resellers who need a copy for training, demonstration, and shared customer support.
We strongly encourage your use of our current logo, and current descriptions. We only require that you allow us to pre-approve the online messaging or relevant branded collateral you propose to re-use or create anew. We will also encourage you to document and share use cases and joint solutions that we can co-promote.
What is the duration of your partner program? What are the renewal conditions?
Depending on the nature of the relationship, there may be no need for formal renewal until a precipitating event like a corporate entity or mission change. Referral agreements usually auto-renew so long as the relationship is ongoing and successful, but may be amended or canceled in the event of a material technical, commercial or legal circumstance. Other agreements with exclusive resale, runtime integration, subscription or support terms, or regulatory renewal requirements for example, can expire annually and/or be subject to other stopping points or conditions,
+ IRI Software Pricing
The perpetual use (CapEx) price of IRI data de-identification software (like IRI FieldShield) is usually based only on the number of hostnames where static data masking jobs run; i.e., wherever the executable/engine (SortCL program) is installed. The price does not vary by the number of cores, IRI Workbench (job design GUI) users, data sources, rows, functions, features, etc.
The same considerations below apply to IRI Voracity (data management platform) licenses which include FieldShield, CellShield EE, DarkShield, RowGen, CoSort, etc. DarkShield licenses used for database (RDB or NoSQL) sources with C/BLOBs are priced the same as FieldShield. For DarkShield masking of files and documents and NO databases involved, pricing per hostname is not fixed but volumetric, yet the same considerations below apply.
Base FieldShield and DarkShield can be purchased standalone (or discounted together) at one-time license fees that cover perpetual use, documentation, and the first year of technical support (for standard use cases). There are discounts on multiple and runtime (see below) licenses, and both FieldShield and DarkShield (as well as CellShield EE and RowGen and other included components) are also available (and more affordable in volume) with Voracity (see below).
At least one license of a standalone product (engine) is needed to mask data, though the base/first Voracity price tier includes five executable licenses. FieldShield users will need at least one (heavily discounted) local dev/test version of the executable in addition to at least one full-priced production server license. With FieldShield, Linux/Unix licenses cost about 1/3 more than the Windows version, but there are discounts for multiple licenses.
Generally, the total number and location of masking licenses needed should take factors like performance, convenience, and budget into consideration:
- In performance terms, the number of licenses may match the number of (major) database servers in use ... particularly where tables volumes are large. While it is not a one-for-one requirement, masking jobs run faster if the masking engines are installed/licensed on each large DB source or target system (to avoid both network and I/O contention). The best way to know your tolerable degradation point on a given install is through testing.
- In convenience terms, it's very common to also license the engine for local use on one or more IRI Workbench client dev/test PCs, where masking jobs are first designed and debugged, as well as on disaster recovery/failover systems. Regardless of the number of licenses however, IRI Workbench is always free to distribute. Bear in mind that remote Workbench connections (like these on Linux) to SortCL licenses installed on Windows servers do not work well due to server side restrictions so it is more practical for Windows users to test CoSort, FieldShield and RowGen with locally installed development licenses (which are also discounted with FieldShield, included in Voracity price tiers, and not an issue with the DarkShield API).
- In budget terms, additional perpetual-use production masking licenses of IRI *shield tools procured simultaneously (along with the first one at full price) are discounted between 20% and 40%. Annual maintenance (support) renewals for those same *shield products are offered at 20% of the paid-up license fee(s), and include upgrades and limited license transfer and disaster recovery rights. Maintenance is included with Voracity platform subscriptions, but offered at lower renewal rates for perpetual use.
Additional Pricing Considerations
1) Voracity also includes one IRI CellShield EE Excel-side license, the DarkShield front-end wizards in Workbench and back-end API, plus the same 5 "SortCL" engines that support FieldShield data masking, DB subsetting, IRI RowGen test data synthesis, NextForm data/database migrations, plus CoSort-powered data integration (ETL) and migration, data quality, analytics, and much more. Voracity has higher tiers for broader deployments (e.g., Tier 2 up to 15 hostnames, Tier 3 up to 50, and so on) where the unit pricing drops in higher volumes, though you can only license in tiers, not per hostname, in the case of Voracity. Annual Voracity (OpEx) subscription license include support whereas perpetual use (CapEx) licenses only include support in the first year.
2) For dynamic data masking applications through the FieldShield 'Sandkey' API library (SDK) or DarkShield RESTful API -- or for runtime decryption sites using either engine without IRI Workbench, documentation, or support -- there is more deeply discounted, volume-tiered, pricing. That is offered in a royalty covenant attached to a primary static data masking development license (which covers IRI support and the other features above). Dynamic data masking performed on the same systems/s) (hostname/s) on which the static data masking license is already installed does not require additional licensing, however.
3) Note that IRI is developing new web application front-end starting with DarkShield, and from there FieldShield and a RBAC-driven dyamic data masking system for various sources. Pricing will differ for these environments. IRI also offers premium bundled options for those interested in advanced DevOps and TDM through data and database virtualization; i.e., IRI-integrated solutions like Windocks (or Actifio or Commvault) or ValueLabs TDH (or Cigniti) for containerized or on-demand database/file instances scrubbed through Voracity masking, cleansing, subsetting or generating jobs.
4) See this FAQ regarding cases where additional or fewer hostname-specific licenses may be needed in the future.
Please contact info@iri.com if you have further questions, or need help pricing an IRI data masking or management product for your environment.
If you need additional hostname copies of a standalone product already purchased, you can buy them under then current pricing under similar terms; i.e., full price on the largest new system with the other systems simultaneously needed at a discount.
If you need fewer licenses, there is no refund, but your annual maintenance base rate will be lowered to reflect your new net license fee basis if you formally de-certify the use and physical removal of the software from the applicable hostname(s).
Because Voracity installations are licensed (for subscription or perptual use) in tiers (hostname blocks), you would only need to consider paying the differential price of a higher tier if the number of additional hostname licenses neeed would take you into that next pricing tier; e.g., from 5 to 6/7 or above 15, 50, 100, or 500. Conversely, decommissioning or non-renewal of Voracity liceneses (upon certification) allows for a lower Tier re-subscription rate at the next 1- or 5-year renewal period, or a re-set of the base maintenance rate in the case of a perpetual use license.
How much does the CoSort package cost?
Per-copy prices, which include the SortCL program, typically range from the mid 4 to 5 figures (USD) and are based on hardware (e.g., RAM on x86 generic PCs, and model number on Unix OEM servers) and the number of cores in use. CoSort is also available by subscription within the IRI Voracity platform which does not take machine sizing into account. Contact your IRI representative for a cost estimate for your environment.
In the perpetual use model, there are discounts for successive licenses ordered at the same time, limited or expiring usage, runtime integration, and GSA schedule procurements. Your company may also have an umbrella (site), or distribution (royalty) agreement in place with pre-negotiated discounts.
Specific and final price quotes are provided under NDA.
How are IRI's other offerings priced?
- IRI Workbench, the graphical IDE built on Eclipse, is included with each Windows or Linux hostname on which a licensed IRI software product (in this list) runs.. A MacOS version is also available on request and is free only to licensees of one of the products below.
- IRI CoSort is priced for perpetual use per hostname according to installed RAM aboard x86 Windows and Linux systems, and the number of licensed threads (ttpically up to the number of available physical cores) on each. On AIX, Solaris, HP-UX and zLinux, prices vary by OEM hardware model.
- IRI Voracity -- which also includes CoSort, NextForm, FieldShield, DarkShield, RowGen, and Ripcurrent, is typically a subscription (one or five years) based only the total number of SortCL-executing hostname licenses, which are usually database or ETL servers. There are additional charges for Hadoop and other integrated (premium feature) options available through our partners. Perpetual use pricing is also available on request.
- IRI FACT (VLDB unload) and IRI RowGen (test data generation) are priced per hostname according to the number of licensed CPU cores (threads) licensed for use on each. Note that FACT is supported in Voracity, but must be separately licensed.
- IRI NextForm has multiple editions and prices. Find details here.
- IRI FieldShield (static data masking) is based on the number of executing hostname licenses only, with higher costs on Linux and outside the US through IRI VARs. Runtime API calls to FieldShield SDK (dynamic data masking) functions are at various percentages of the full package price depending on volume.
- IRI CellShield and IRI DarkShield pricing is based on the number of spreadsheets / documents that need protecting. DarkShield costs the same as FieldShield however, when used to mask data in a relational or NoSQL database.
- IRI Data Masking as a Service (DMaaS) is performed at daily, hourly, or per-project rates.
Refer to the licensing information in each product section on this site for price ranges. Contact your IRI representative for more information and an NDA-confidential quotation for the use of any IRI software product, or for an IRI Professional Services engagement estimate.
It may be included in your license fee in the first year, and then become an annual option at a percentage of the license fee that reflects the desired level of support and upgrades.
Annual support is typically renewed at 20% of the license fee basis for the hardware for direct US customers only. This level entitles you to product updates and limited license transfer rights.
If support lapses, back support is owed and major new release may be required and offered at a discount.
24/7 support is an additional premium that only some sites request or require.
The software does not expire. IRI's default business model allows you to keep running forever, with or without support. So, you do not have to pay us all over again at the end of some multi-year term, unless you have specifically requested and are paying us to lease instead.
+ ISV (OEM) Integration
The CoSort package comes with all the tools, conversion utilities, and callable libraries, as well as full .pdf documentation for the executables and APIs.
When a CoSort package is installed, default system tuning parameters are automatically configured to exploit available RAM and CPU resources. Users can manually adjust their tuning parameters (including the assignment of sort overflow disks, and audit logs) in a simple text file.
Usually through system-specific license keys. Call us to describe your situation.
How long will it take to integrate CoSort?
That depends on what component(s) you choose to apply, and the extent of functionality you need. For a basic sort, it may take as long to choose an interface as to implement one. Implementing custom user input, compare, or output routines, or write custom, field-level transforms (i.e. adding your own cleansing or statistical functions for individual fields) will take longer.
How much are CoSort royalties?
From USD$150 to $15K per copy, or site, when embedded and redistributed within your application. It depends on what piece you integrate, how many and how quickly you distribute them, plus the (average) size of end-user hardware and cost of your application. We aim for fair licensing within your business model.
Is CoSort tuning only global, user, or job specific?
Actually, it can be any (combination) of the above.
You can choose to invisibly embed, re-license, or refer a full or partial CoSort package. Partial options include:
• Standalone interfaces: sorti, sortcl
• Third-Party Sort PlugIns: e.g., Unix sort, SAS, etc.
• Runtime libraries: cosort_r(), sortcl_routine()
What kind of performance (improvement) can I expect?
That depends on your current methodology, hardware, kernel and CoSort tuning, data volume, and job specs. You can measure it during a free, confidential trial.
Will I pay for a development copy? How much?
If so, less than you would for production. Call IRI to discuss your situation.
+ Job Monitoring, Recovery, and Logging
How do I know the process status during execution?
If you are executing Voracity jobs in Windows, Linux, or other Unix file system using the default CoSort/SortCL (or subset) program, that executable can send event (job status) messages to the (CLI or GUI) console at various verbosity level (most basic shown below).
If you are executing Voracity jobs in Hadoop MR2, Spark, Storm, or Tez, the HDFS job inventory indicates status:
What are the recovery mechanisms available?
We believe that Hadoop provides for this automatically. Default CoSort/SortCL-based executions only allow for pause/resume in the event of insufficient soft overflow (temp) file space.
What kind of audit data and dev ops data can be available from job execution?
There are several logs generated, including SortCL app stats, error logs, and a self-appending runtime performance file. There is also an optional XML audit log file generated from each run showing the contents of the script and environment details:
+ Large XML File Creation/Conversion
Can CoSort's SortCL tool sort, join, and report on XML files?
Yes, as long as your XML files describe structured, sequential records. The output can be another flat XML file, or any another file type that SortCL supports.
Can I convert XML to other file formats?
Yes, if the XML file contains structured, sequential records, and the output process type is documented in SortCL.
Can I create XML files from other file formats?
Yes, if those other process types are documented in SortCL. Any valid output targets can also be custom-formatted and protected for reporting, hand-offs, and outsourcing.
Yes, subject to the format limitations defined above.
Is there a limit to XML file sizes that I can process?
No, unless you run out of disk space.
+ Master Data
IRI Voracity's new Data Unification wizard follows the consolidation style of MDM, and allows you to compare, reconcile, and bucket new master values using fuzzy matching logic.
Alternatively, you can manually move the master data to a central place and metadata repository where it is easier to clean, manage risk, and support a SOA chain. Define the files and fields in the CoSort SortCL tool readable format and scan for naming and attribute discrepancies. Create SortCL jobs to integrate and standardize these files, and leverage custom, field-level transformation functions to cleanse the data according to your own business rules. Once prepared in the file system via rapid CoSort SortCL operations, you can then re-populate master data tables as needed. SortCL join operations can also filter and report on changed master data that are in files.
CoSort's SortCL tool can apply the necessary security filters to help you enforce your need-to-know rules, and to encrypt and anonymize specific file data at risk before it is exposed. You must mask your master data at the field level if you need to test or outsource this data -- or provide views to different departments -- and leave less-sensitive data still accessible.
How can we log and trace these corrective and protective procedures conducted in this tool?
All CoSort (SortCL) application scripts (whether for data transformation, reporting, protection or prototyping) are parsed and saved with runtime information in audit logs that you can secure and query with your preferred XML application or SortCL itself.
The SortCL program in IRI CoSort can flatten and process some hierarchical data, including mainframe index files, to prepare for DB loads and business intelligence tools. SortCL can also join product data with customer transactions (as well as other files with common keys) and output custom reports. These reports can include aggregation and cross-calculation of the detail and summary data produced. SortCL can also perform field-level lookups to find discrete values, and populate newly formatted files.
+ Custom Transformations
Are there any limits to the type of transform I can use?
At the field-level, you cannot link custom transformations that require file-level information, such as statistics. However, SortCL already supports file and record-level aggregation, plus cross-calculation, for detail and summary reporting.
SortCL sends the field data to the routine, which then sends it back in the transformed state, formatted per the other attributes in the output field description.
How would I specify my own transform or vendor library?
Write or license a library and specify it at the top of a SortCL job script (which can also be invoked in a thread-safe API call). In the /INREC or /OUTFILE phase of the script, define the library as a field attribute.
+ Oracle Acceleration
Can I speed unloads without FACT?
Dumping the data to a flat file or pipe into CoSort without qualifiers encumbering the unload can help. So, save the order by, group by, distinct and join work for CoSort -- which can handle them all (at once) faster in the file system, and give you formatted reports in the same IO.
How can CoSort improve my GROUP BY performance?
CoSort's SortCL supports all SQL aggregate functions, including sum, average, count, maximum and minimum. But SortCL is more efficient in that it can sort on multiple keys and produce aggregate results for one or more output files in the same pass through the data, off-line.
How can CoSort improve my JOIN performance?
On an ia64 hp server rx5670 with four 1GHz Itanium2 CPUs and 32GB of RAM, Oracle 9i's SQL*Plus joined two 1G tables in 48 minutes. Unloading the same tables with the IRI Fast Extract (FACT) tool, piping these to flat stream sorts and joins in the CoSort SortCL program, and then piping the result into SQL*Loader built the same joined table in 18 minutes (or, ~1/3 the time of the on-line method).
How can CoSort speed Oracle loads?
Direct path, pre-sorted loads are the fastest way to build new tables since this loading method bypasses the overhead of Oracle's index sort. For bulk loads, CoSort the data first on the primary index key; the create index will bypass the sort step. For regular insertion loads, CoSort the data on the clustered index as the key.
How does FACT improve extract performance?
Through database-specific APIs and parallel unloading techniques that produce portable flat files. For interface details, and to request a brochure, white paper, webinar or trial, go to Products > FACT
How would CoSort replace SQL procedures?
CoSort (or Voracity) SortCL job scripts can do many of the same jobs much faster, and with far less coding. SortCL runs outside the database on flat file inputs, using the same relational logic and functions; i.e. SELECT WHERE, DISTINCT, ENCRYPT, ORDER BY, GROUP BY, JOIN. For example, CoSORT's SortCL uses conditional /INCLUDE and /OMIT statements to select from sequential input sources and output targets. DISTINCT is similar to /NODUPLICATES, ORDER BY is a /KEY, GROUP BY may be a /SUM, /AVERAGE, etc.
Like FACT, both the AnalytiX DS Mapping Manager or Meta Integration Model Bridge (MIMB) from Meta Integration Technology, Inc. (MITI) can automatically convert the file layout metadata used in your relational or ETL tool into CoSort/SortCL data definition file (DDF) format.
+ Support Site
You can work with an IRI engineer directly by completing the Support Request Form, sending a descriptive email to support@iri.com, or by calling 1-321-777-8889, main menu option 3 (for Technical Support).
Why isn't more content posted here?
A list of frequently asked technical questions pertinent to installation and configuration for customers under maintenance agreements is posted and answered in the protected support section of this web site. Nonetheless you can still find many technical and how-to answers available from support@iri.com and the self-learning page here (even if you are not under contract).
+ Synthetic Test Data (RowGen-specific) Questions
Yes, all of the above, and more. See the data sources and targets listed generally under:
https://www.iri.com/products/workbench/data-sources
Note that RowGen can produce all of these targets simultaneously in fact, from the same source of synthetically generated (or masked) data, as well as detail and summary reports with customer formatting in each.
RowGen v3 pricing starts well below $10K for perpetual use, and increases proportionally with additional CPU cores that you may wish to exploit. Maintenance is free in the first year and then 15- 20% of your license fee, depending on the level of upgrades.
What does RowGen do besides 'generate rows'?
It reads popular data model and file layout metadata to formats the rows of test data into precise flat file, reporting, and database table structures for DB populations, and preserves the referential integrity of those tables. RowGen is a complete solution for test data, as it allows you to be simultaneously:
- Generating Huge Volumes in Parallel
- Applying Custom Rules and Ranges
- Using DB Data Models and Metadata
- Preserving Realism and Relationships
- Transforming, Segmenting, and Reporting
- Formatting in Custom File Layouts
- Auditing Jobs to Verify Compliance

{kind=link}
{kind=link}