Challenges
Applications and databases have their own logic and unique properties. To have realistic test data for software testing, you must make sure it reflects characteristics of production data, such as:
- selection conditions (business rules)
- column attributes and transformations
- inter-field/key relationships (referential integrity)
- value ranges and inter-column calculations
Production-quality test data must also have these attributes:
- type - correct column / field values and formats
- width - values with current (and future) ranges
- frequency - realistic value occurrence patterns
- depth - volumes that address scalability concerns
In fast-paced DevOps and Continuous Integration (CI) / Continuous Deployment (CD) environments, the ability to generate and automate consistent, and realistic test sets on-demand that can range widely in format and volume can be a tall order, distracting programmers with tight delivery timelines. And of the many DevOps test data management tools available, few are sufficiently robust, ergonomic or affordable.
Solutions
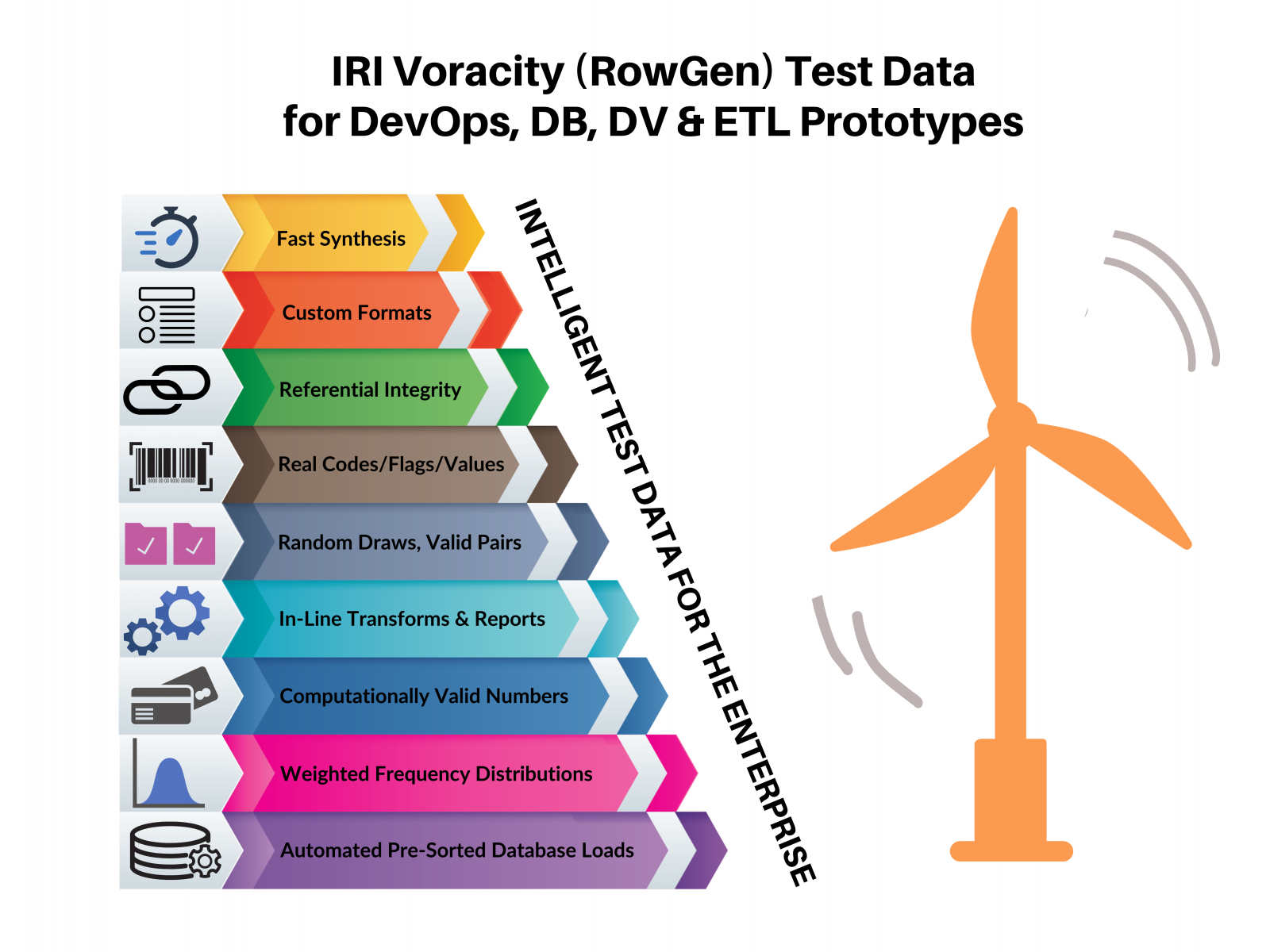
Applications developed with realistic data formats and volumes are more likely to succeed in production. The IRI RowGen test data generation tool uses production metadata to synthesize custom test sets with randomly-generated data, and/or randomly selected data from production sources. The IRI FieldShield and IRI DarkShield data masking tools can also be used to find and mask PII and other sensitive data in production, and create secure targets into lower environments for testing.
To generate the right values and value ranges, RowGen uses conditional selection and formatting parameters. RowGen further enhances test data realism through referential integrity, frequency distributions, and built-in transformation and formatting functions. For example, you can randomly select data and specify ranges from pools of real data and weighted numbers (respectively).
For test data automation in DevOps, a/k/a Continuous Integration and Continuous Deployment or Delivery (CI/CD), environments, RowGen can synthesize test data at any step in a development process without depending on data being made available from another step. See linked examples of automated test data provisioning for DevOps at the bottom of this page.
Moreover and uniquely, embedded data transformation, validation, and formatting functions can run simultaneously against the generated data in the same script! This can facilitate incremental application tests that assure backwards compatibility and forward compliance with your production releases. See this use case.
Combine random generation and set-file selection, field-level conditions and manipulations, and custom layout features. Rapidly build the intelligent data you need to stress-test and vet your applications. Improve the quality and reliability of your deliverables. Schedule jobs to repeat generation and testing operations in IRI Workbench (or your own CLI-supporting automation tool) to smooth out CI, and enable CD, processes.
If you still prefer to test with real data (from production DBs or files), you can also use RowGen to quickly subset it, or you can mask an even broader range of sources with IRI FieldShield and IRI DarkShield. If you need multiple capabilities, or need to virtualize test data from a variety of static or streaming sources, check out the IRI Voracity data management platform and partners like Value Labs, and their Voracity-supporting Test Data Hub which provides test data on-demand.
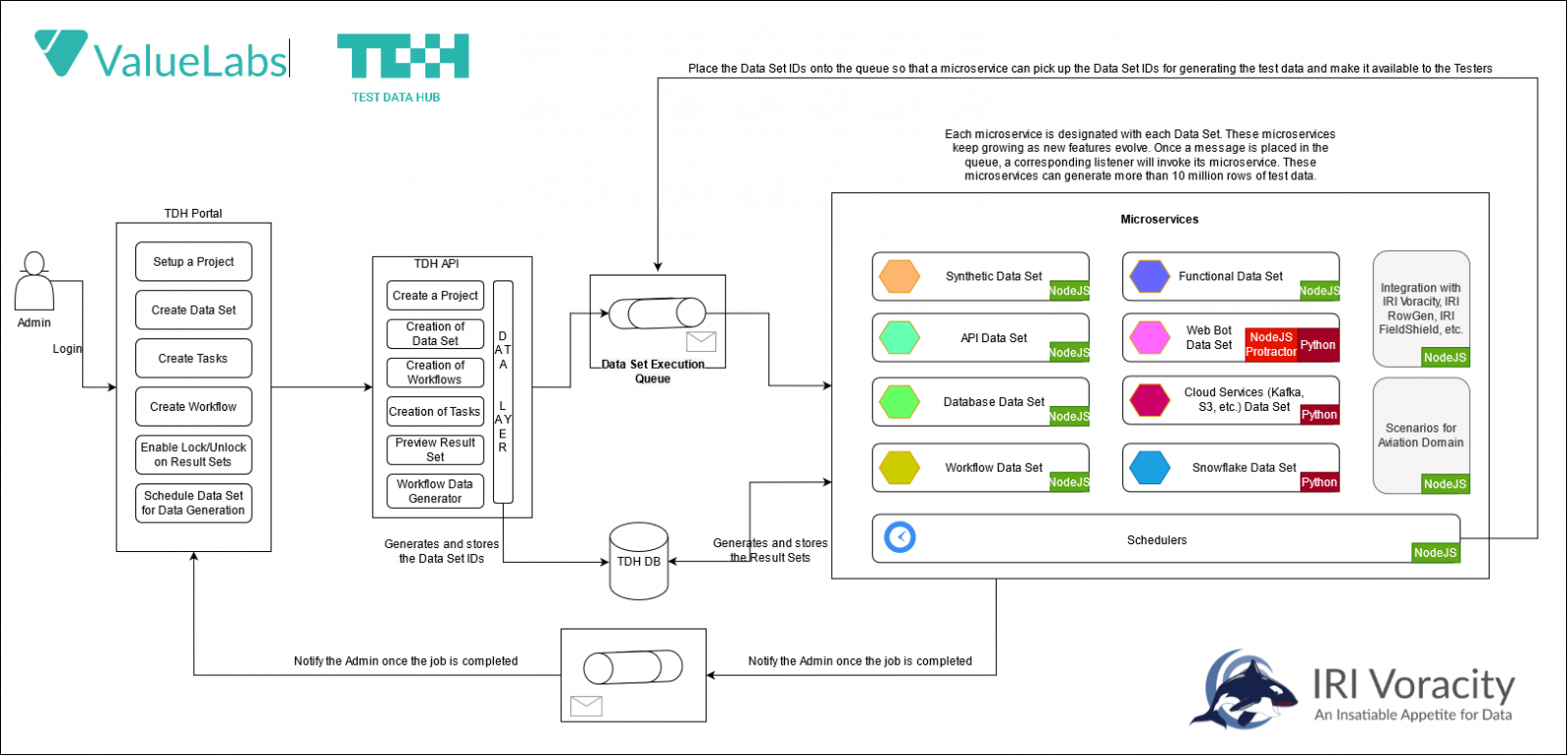
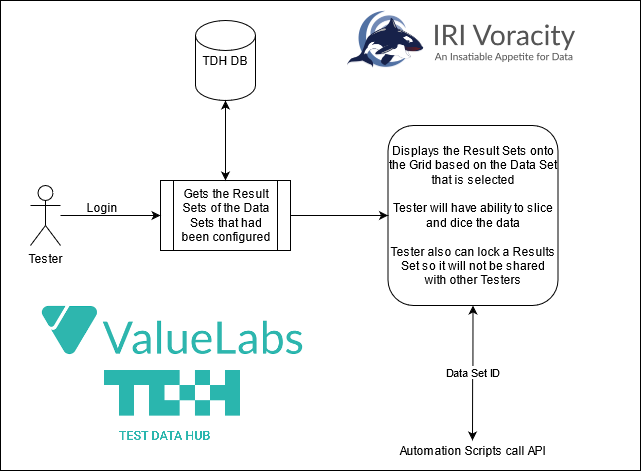
And if you use and existing CI/CD pipelines, you can call IRI software directly to provide masked, subsetted of synthesized data into them! See the examples of test data generation for DevOps done in: Amazon CodePipeline, Azure DevOps, GitLab and Jenkins. If you use another test data automation framework, ask us about it!
