Challenges
Data sorting and merging remain critical components of data processing. These tasks are part of:
- database load, index, and query/search operations
- data warehouse sort, join, and aggregate transformations (ETL jobs)
- reporting, analytical, and testing environments
But as data source sizes increase, from hundreds of megabytes into terabyte levels and beyond, sorting can place an exponential demand on computing resources. Most standalone data sorting tools and techniques, as well as many data merging methods, simply cannot scale to meet the demands of big data.
The sort functions in databases, ETL and BI reporting tools, operating systems, and compilers are just not designed for big data either. Meanwhile, legacy sort/merge utilities are expensive to operate, use cryptic JCL syntax, and are functionally limited.
This chart summarizes some of the problems found in the high volume sort tool market:
|
Robustness Issues |
Management Concerns |
|---|---|
| sort speed and scalability in volume | sorting and related functionality |
| data and file type support | GUI and/or parm syntax simplicity |
| event monitoring and debugging | logging and metadata frameworks |
| performance tuning and logging | pricing and licensing models |
| plug-in compatibility or parm conversion accuracy | technical support speed |
| third-party hardware and software interoperability | vendor capabilities and compability |
| implementation paradigm | skills gap (e.g. Hadoop), maintenance costs |
Solutions
As the volume of data grows, so grows the value of IRI CoSort. CoSort was the world's first commercial sort/merge software package for use on "open systems" and since 1978 remained the leader in commercial grade sorting, and a proven:
- Unix file sort utility
- Windows sort program
- ETL, BI, and DB sort verb alternative
- Mainframe JCL sort/merge replacement
with state-of-the-art performance, industry-leading functionality, and the most familiar, intuitive user interfaces ... and without forcing its users to buy more hardware, Hadoop, in-memory DBs, or appliances to get big data jobs done.
CoSort will sort any number, size, and type of structured fields, keys, records, and files -- including mainframe binary, IP addresses, multi-byte Asian characters, Unicode, and so on. The CoSort engine scales linearly in volume, and allows granular tuning of CPU, memory, disk, and related resources. Multiple gigabytes sort in seconds on multi-CPU servers.
127,268,900 rows * 405 bytes/row = 51.5GB input file
CoSort total job time w/20-byte sort key @ 131 seconds = 2m:11s
Platform: x86 Linux development server using 32 of 64 cores
CoSort can also replace or convert third-party sort functions with proven libraries, tools, or services - saving time and money in batch operations and embedded applications. Ask about special incentives for migrating from a legacy sort product, and discounts for integrated distribution.
Sorting is Just the Beginning
CoSort also delivers the unique ability to simultaneously transform, migrate, report, and protect data at risk. The CoSort Sort Control Language (SortCL) program combines these functions in the same job script and I/O pass. Map multiple sources to multiple targets and formats while you sort.
SortCL is only one of several interfaces in the CoSort package available for standalone or integrated sort/merge operations. All sorting and transformation jobs can be scheduled, monitored, logged, audited, and otherwise managed in the IRI Workbench GUI, built on Eclipse™.
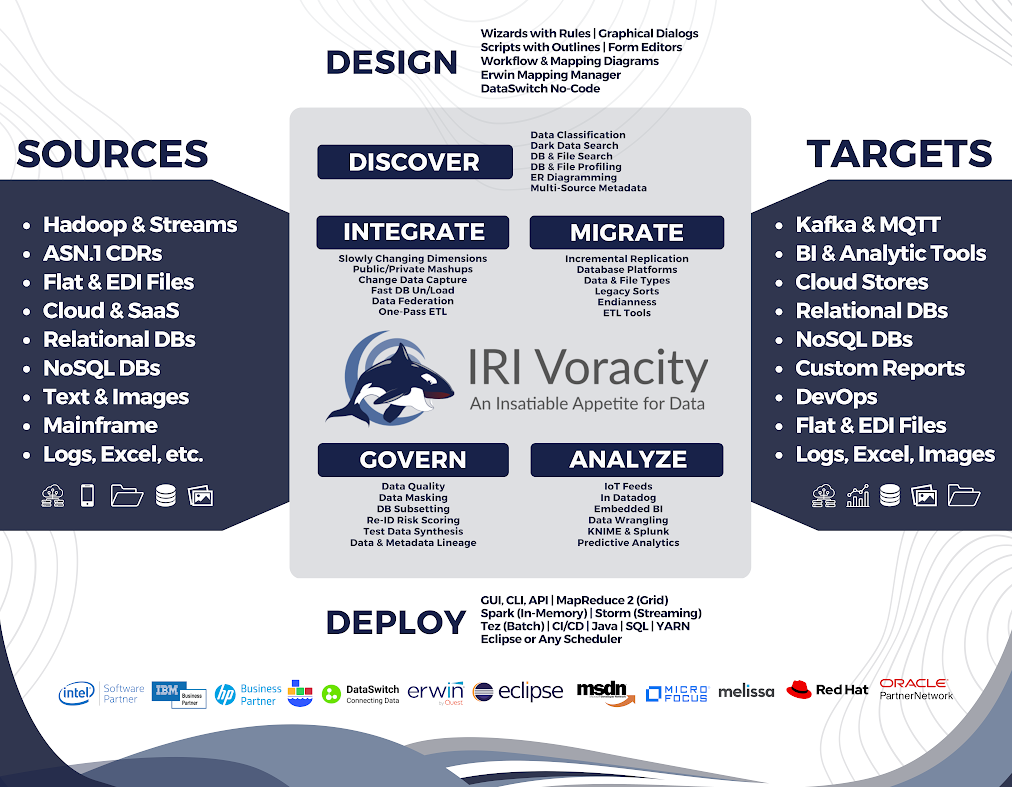
Beyond the CoSort package, these same SortCL-driven operations are also integral to the CoSort-including IRI Voracity data management platform where big data discovery, integration, migration, governance, and analytics are performed and combined. In Voracity, the CoSort sort engine (and SortCL scripts) are automatically used in (and created for): ETL, change data capture, DB subsetting, pseudonymization, synthetic test data, data wrangling, and bulk DB loading operations.