Data quality assurance and improvement are essential components of data integration, data governance, and analytics. Why? Simply put, "garbage in, garbage out."
In addition to normal mistakes and duplication, enterprise data undergoes constant change. In the US alone, for example, 240 businesses change addresses and 5,769 people change jobs every hour. Your employees need to be able to trust the data sources for their reports and applications.
According to Gartner, "33% of Fortune 100 organizations will experience an information crisis, due to their inability to effective value, govern, and trust their enterprise information."
36% of participants in the Gartner study estimated they were losing more than $1 million annually because of data quality issues, while 35% were unable to estimate the cost impact.
Users of the IRI Voracity total data management platform, or its component products like IRI CoSort, can control data quality and scrub data in many different sources in many different ways:
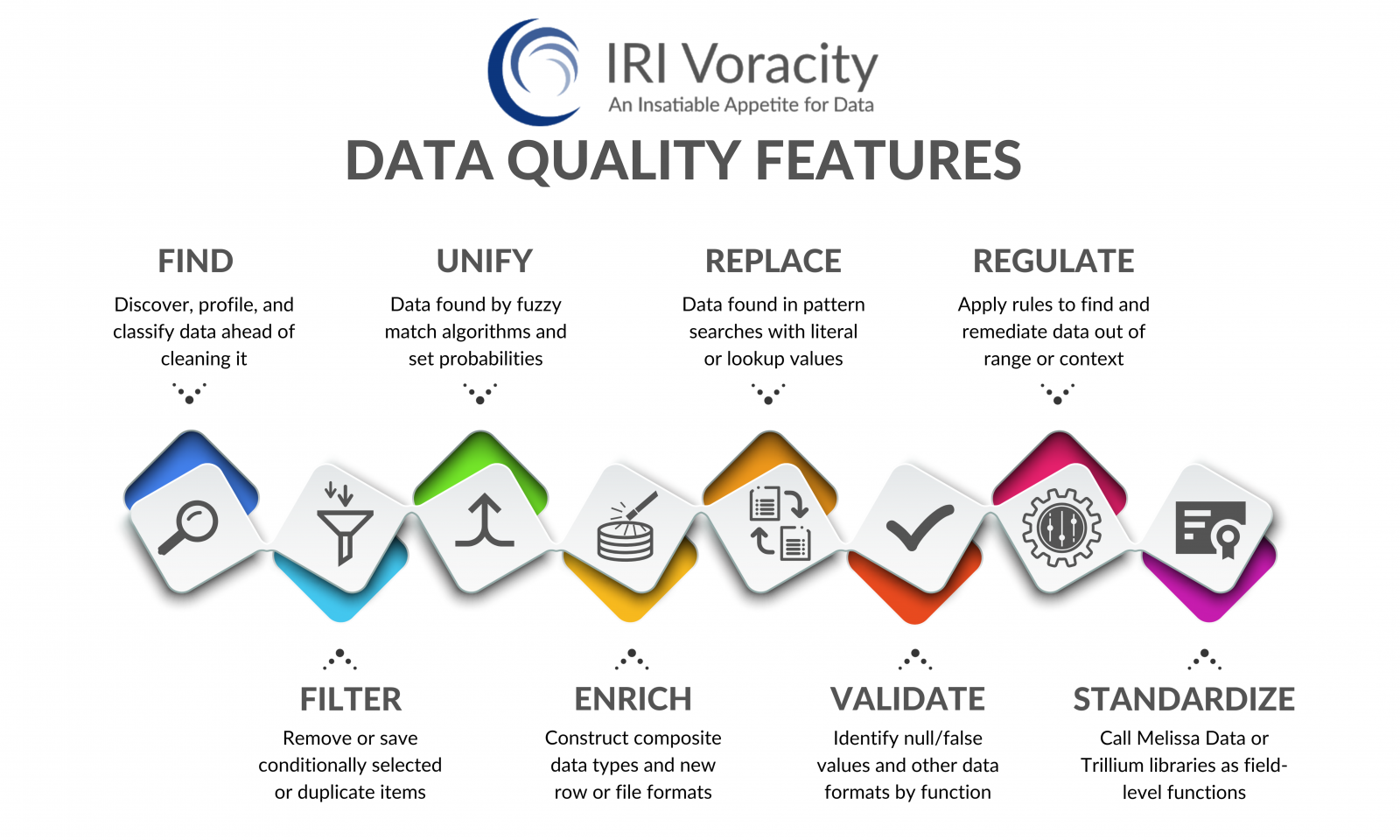
| Capability | Options |
|---|---|
|
Profile & Classify |
Discover and analyze sources in data viewers and the metadata discovery wizard. Those facilities along with flat file, database, and dark-data profiling wizards in the IRI Workbench (Eclipse GUI) allow you to find data values that exactly (literal, pattern, or lookup) match, or fuzzy-match (to a probability threshold), those values. Output reports are provided in CSV format and extracted dark data values are bucketed into flat files. New classification facilities allow you to apply transformation (and masking) rules to data categories. |
|
Bulk Filter |
|
|
Validate |
Use pattern definition and computational validation scripts to locate and verify the formats and values of data you define in data classes or groups (catalogs) for the purposes of discovery and function-rule assignment (e.g., in Voracity cleansing, transformation, or masking jobs). You can also use SortCL field-level if-then-else logic and 'iscompare' functions to isolate null values and incorrect data formats in DB tables and flat files. Or, use outer joins to silo source values that do not conform to master (reference) data sets. Use data formatting templates and their date validation capabilities, for example, to check the correctness of input days and dates. |
|
Unify |
Use the consolidation-style (MDM) data consolidation wizard in IRI Voracity to find and assess data similarities, and remove redundancies. Bucket the remaining master data values in files or tables. Another wizard can propagate the master values back into your original sources, and data class discovery features locate like (identical and similar) data found across disparate silos. |
|
Replace |
Specify one-to-one replacement via pattern matching functions, or create multiple values in sets used for many-to-one mappings |
|
De-duplicate |
Eliminate duplicate rows with equal keys in SortCL jobs |
|
Cleanse |
Specify custom, complex include/omit conditions in SortCL based on data values. See this page for more details. |
|
Enrich |
Combine, sort, join, aggregate, lookups and segment data from multiple sources to enhance row and column detail in SortCL. Create new data forms and layouts through conversions, calculations and expressions. Enhance layouts by remapping and templating (composite formats). See IRI NextForm. Produce additional or new test data for extrapolation with IRI RowGen. |
|
Advanced DQ |
Field-level integration in SortCL for Trillium and Melissa Data standardization APIs, etc. |
|
Generate |
Use RowGen to create good and bad data, including realistic values and formats, valid days and dates, national ID numbers, master data formats, etc. |
Learn more from this Bloor Research article on improving data quality using IRI Voracity platform software.
