Challenges
Most ETL tools, along with the database engines they use, cannot transform big data efficiently without:
- an expensive parallel processing edition
- taxing database or system resources
- a complex, hard-to-maintain Hadoop environment
- a 6/7-figure hardware appliance or server upgrade
- pushing the problem to an even more expensive database
It is the large sort, join, and aggregation jobs that can take too long. Subsequent tasks like loading, analytics, or BI displays also suffer. And these E, T, and L steps are typically performed in separate steps, I/O passes, products, or constantly changing cloud configurations.
Solutions
If you have a data warehouse, chances are ETL tool efficiency is an issue. IRI extraction and transformation utilities like FACT (Fast Exract) and CoSort -- or the IRI Voracity ETL and data management platform which supports them -- deliver ETL tool speed enhancement simply by running inside or alongside ETL tools running on-premise or in the cloud.
Easily design these jobs in the free IRI Workbench GUI for all IRI software, and call them from the command-line task in your ETL tool:
| Operation | IRI Product | Supports | Advantages |
|---|---|---|---|
|
IRI FACT (Fast Extract) |
Oracle, DB2, Sybase, MySQL, SQL Server, Altibase, Greenplum, Teradata, Tibero |
Native DB drivers, parallel unloads, portable flat file output data, simple job scripts, easy to invoke |
|
|
DB-agnostic, all flat files, Informatica, DataStage, and any 'system command' call |
Multi-threading, task and I/O consolidation, local and remote execution in LUW file systems or Hadoop, plus automatic metadata and job creation |
||
|
All RDBMS loaders, ODBC, and JDBC |
Stream pre-CoSorted data after E or T jobs to shave up to 90% off load time |
||
|
More than 125 legacy and modern small and big data sources and targets |
All of the above in a total data management environment combining data discovery, integration, migration, governance, and analytics in Eclipse |
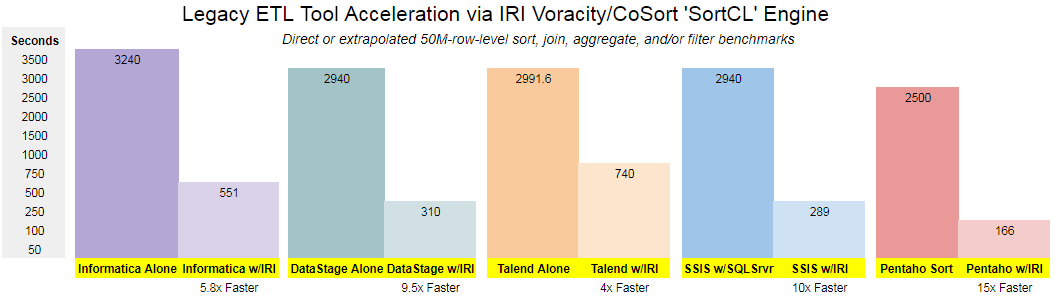
Optimize sort, join, and aggregation transforms in Inormatica, DataStage, Talend, Pentaho, ODI and other tools using the SortCL engine in the CoSort product or Voracity platform powered by CoSort. Many SortCL jobs can also run seamlessly in Hadoop, and are invoked by other tools at the API or script level; e.g., in Kalido, ETI, Software AG Natural, SAS, and TeraStream.
Use the metadata and workflows you have, and just call a SortCL task from your ETL tool to speed, and/or combine unloads, data transformations and operations like:
- Sorts
- Joins
- Aggregates
- Lookups
- Perl-Compatible Regular Expressions
- Data-type and file-format conversions
- Field/column encryption and masking
- Detail, delta (CDC) and summary reports
- Row-column pivoting
- Slowly changing dimension reports
- Test data generation
You can also call IRI jobs from the shell (as a batch executable or ETL tool command), via API or Eclipse GUI -- and flow data back and forth through tables, files, pipes, or API procedures as needed. In the IRI Workbench GUI environment, you can build the individual job specs or complete ELT or ELT flows connecting CoSort (or FACT) to your sources and targets.
DataSwitch, Quest (formerly Erwin and AnalytiX DS), and Meta Integration Model Bridge (MIMB) software or services can also convert metadata defined in popular ETL tools (like Informatica .xml and DataStage .dsx repositories) into equivalent Voracity data (and/or job) specs if you want to re-platform those mappings to save money and time. This automatic metadata replication preserves your existing design investments, facilitates job creation, and reduces migration costs.
Solution Links
Blog Articles
Other Resources
